What is actually inside an AI agent
A practical breakdown of what actually sits inside an AI agent in 2026: the decision loop, tools, memory, checkpoints, policies, approvals, tracing, evals, and the line between a workflow and a full agent runtime.
read this first
The most common mistake is simple: people see a model with tool calling and immediately call it an agent. That is enough for a demo. It is not enough for a system that must keep state, recover from a bad step, ask for approval, and leave a clear trail after a failure.
The confusion begins because different communities use the word agent for different layers of the system. For some, an agent is any loop that can call tools. For others, an agent is already a governed runtime with policies, approvals, memory, and observability. Both are describing something real, but they are describing different scopes.
The DOU article and discussion show this split well. The article itself explains the base loop clearly, but the comments bring in an important objection: a serious agent is not just 'a brain in a loop', it is a managed execution unit with explicit operational boundaries. [1] That is exactly why simple demos and production systems feel like different categories of software.
Anthropic has recently stayed close to a simple lower bound: an agent is an LLM that autonomously uses tools in a loop. [2] That is a useful baseline. It separates an agent from a one-shot completion. But it is still only the lower bound, not the whole system.
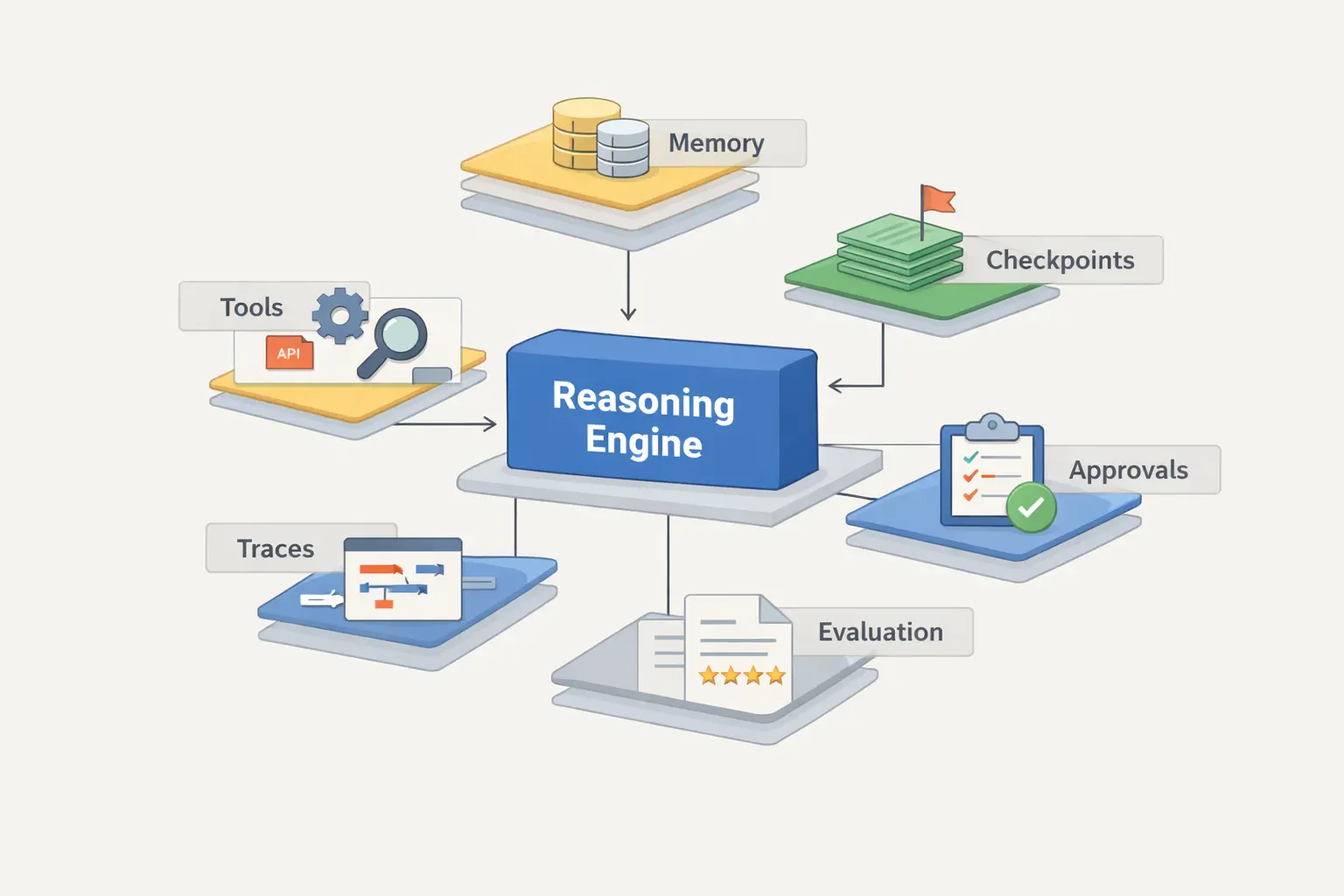
In practical terms, you can frame it like this: the agent starts at the loop, but the useful product starts at the runtime around the loop. Once the system can search, read, write, execute code, and call APIs repeatedly, the main problems shift away from generation quality and into control, state, and failure handling.
At the center of the system there is a repeated loop. A request or goal arrives. The model reads the current context. It chooses the next action. That action may be a normal answer, a structured output, or a tool call. Then the environment returns a new observation, and the loop repeats until a stop condition is met.
This is the part most people notice first. It is also the easiest part to explain. In Anthropic's Agent SDK material, the common feedback loop is described as 'gather context -> take action -> verify work -> repeat'. [3] For many production agents, that is a very accurate simplified picture, even though the runtime around the loop becomes much more elaborate.
A minimal implementation can genuinely be short. The DOU piece is right about that. A basic loop with tools, prompt state, and a max-step guard fits into a fairly small amount of code. [1] But short code does not mean a simple system. It usually means that complexity has been moved into separate services, tool contracts, memory handling, and operational safeguards.
Here is a deliberately stripped-down version of the mechanism. It is short on purpose so the boundaries stay obvious:
messages = [system_prompt, user_request]
steps = 0
while steps < MAX_STEPS:
response = model.run(messages=messages, tools=TOOLS)
if response.final_output:
return response.final_output
if response.tool_calls:
for call in response.tool_calls:
result = run_tool(call.name, call.arguments)
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": serialize(result),
})
else:
messages.append(response.message)
steps += 1
raise RuntimeError("Agent exceeded max steps")If you only read this loop, you can see where an agent begins. But it is still not enough to explain why one agent stays stable, another becomes expensive, and a third quietly accumulates risk until it breaks under real usage.
Takeaway
The loop explains agent behavior. By itself, it does not explain quality, cost, or safety.
Once you move beyond toy agents, the key question is no longer whether the model can call a tool. The real question becomes: under which rules is it allowed to act, what state does it carry, what gets stored, what requires approval, and how will you inspect a bad run after it fails.
OpenAI's release on building agents is useful here because it is not framed as model calls alone. The announcement highlights built-in tools, orchestration, and integrated observability for tracing workflow execution. [4] That is an important signal: even platform vendors now frame agent building as a runtime problem, not just a prompt problem.
The same pattern shows up in framework docs. LangGraph's persistence docs talk about checkpoints, threads, replay, time travel, and fault tolerance. [6] Microsoft Agent Framework puts observability front and center and routes traces, logs, and metrics through OpenTelemetry. [7] These are not side features. They are the pieces that let teams debug, recover, review, and control long-running behavior.
A useful working model is this: goal and permissions at the top, planning policy below them, then tool access, then state and memory, and a control plane around all of it with tracing, evals, approvals, and rollback. The model matters a lot, but it is still only one layer inside the full structure.
Takeaway
The more freedom an agent gets, the more runtime scaffolding has to exist around the model.
This distinction matters because teams often pull agent infrastructure into problems that are really just workflows. The result is a system that costs more, is harder to test, and still does not gain enough extra capability to justify the trade-off.
Workflow
Agent runtime
Bad middle ground
The system looks autonomous, but has no clear permissions, no stop rules, no replayable history, and no reliable review surface. That is where teams end up with expensive demos that are hard to trust and even harder to debug.
Rule of thumb
If the path is already known, start with a workflow. Reach for an agent only when the route itself has to be discovered during execution.
| Comparison point | What it usually means | Why it matters |
|---|---|---|
| Current context window | The active prompt, recent messages, tool results, and working state of the current run. | This is the first place that breaks when an agent loops too long or accumulates too much noisy tool output. [1][5][9] |
| Checkpoints or thread state | Saved execution snapshots from which a run can be resumed, replayed, or inspected later. | This is what makes human approval, interruption, debugging, and recovery after failure practical. [6] |
| Long-term memory store | Longer-lived facts, user preferences, or summaries stored outside the current context window. | Useful when the agent needs continuity across sessions, but risky when the memory policy is vague or the data becomes stale. [5][6] |
This layer turns an autonomous demo into an engineering system. Without it, production use becomes hard very quickly.
No approval boundary. If the agent can trigger side effects without human review where review is required, the system becomes fragile fast.
No eval discipline. Anthropic is direct on this point: capability evals, regression suites, transcript review, and continuous checks stop being optional once the system matters. [8]
No rollback or recovery path. If a step fails halfway through and the system cannot resume or replay from a known state, the operator ends up effectively blind. [6]
Summary
The more autonomy you grant, the more control plane you need around it. Otherwise the system is only agentic in the least useful sense: it acts on its own, but nobody can govern it well.
If you want one section you can drop into an architecture review, use this one.
Ask where the path is actually decided.
If the route is mostly fixed in code, call it a workflow. If the system discovers the route while it is already running, you are in agent territory and should budget for additional control layers right away.
Treat evaluations like unit tests for behavior.
Agent quality drifts unless you keep a regression suite, read transcripts, and continuously run key scenarios. This becomes obvious as soon as models, prompts, or tools change. [8]
Bottom line
There is no magic inside an AI agent. There is a loop wrapped in state, rules, tools, and a control plane. Teams get into trouble when they ship the loop and forget everything that should sit around it.
At the minimum level, often yes. But in engineering practice that only describes the lower bound. A serious agent usually still needs state policy, tracing, approvals, recovery paths, and evaluation logic.
They usually focus on the model and the tools, but miss the runtime around them. Memory policy, checkpoints, observability, and approvals often matter more than one extra prompt trick.
A workflow is the better choice when the route is already known and should stay explicit in code. An agent is useful when the route itself must be discovered during execution and the added control-plane complexity is justified.
Because agents act across many steps, tools, and intermediate states. Without evals, teams often notice regressions only after they hit users or expensive production environments.
Primary sources used for this article. Verified on March 20, 2026.
Related Articles
AI Assistant Development Cost in 2026: RAG Chatbots, CRM Integrations, Guardrails, and Support
A practical buyer guide to AI assistant development cost in 2026: prototypes, RAG chatbots, knowledge-base assistants, CRM and website integrations, guardrails, evaluations, monitoring, and support.
AI-assisted attacks and prompt injection in 2026: the new attack surface for AI products
AI-assisted attacks and prompt injection in 2026: the new attack surface for AI products. A practical PAS7 Studio security guide with threat model, controls, rollout checklist, pitfalls, and sources.
AI for landing page development: where it speeds up launches and where it hurts conversion
A practical research piece on using AI for landing page development: v0, Webflow AI, Builder.io, Framer-like builders, UX generation, copy, SEO, personalization, A/B testing, template risk, accessibility, security and technical debt.
AI SEO / GEO in 2026: Your Next Customers Aren’t Humans — They’re Agents
Search is shifting from clicks to answers. Bots and AI agents crawl, cite, recommend, and increasingly buy. Learn what AI SEO / GEO means, why classic SEO is no longer enough, and how PAS7 Studio helps brands win visibility in the agentic web.
Professional development for your business
We create modern web solutions and bots for businesses. Learn how we can help you achieve your goals.