Codex Subagents: How They Actually Work
A practical breakdown of OpenAI Codex subagents in 2026: what OpenAI actually shipped, how to use them, where they create real wins, where they only add noise, and how they affect limits, credits, and speed.
read first
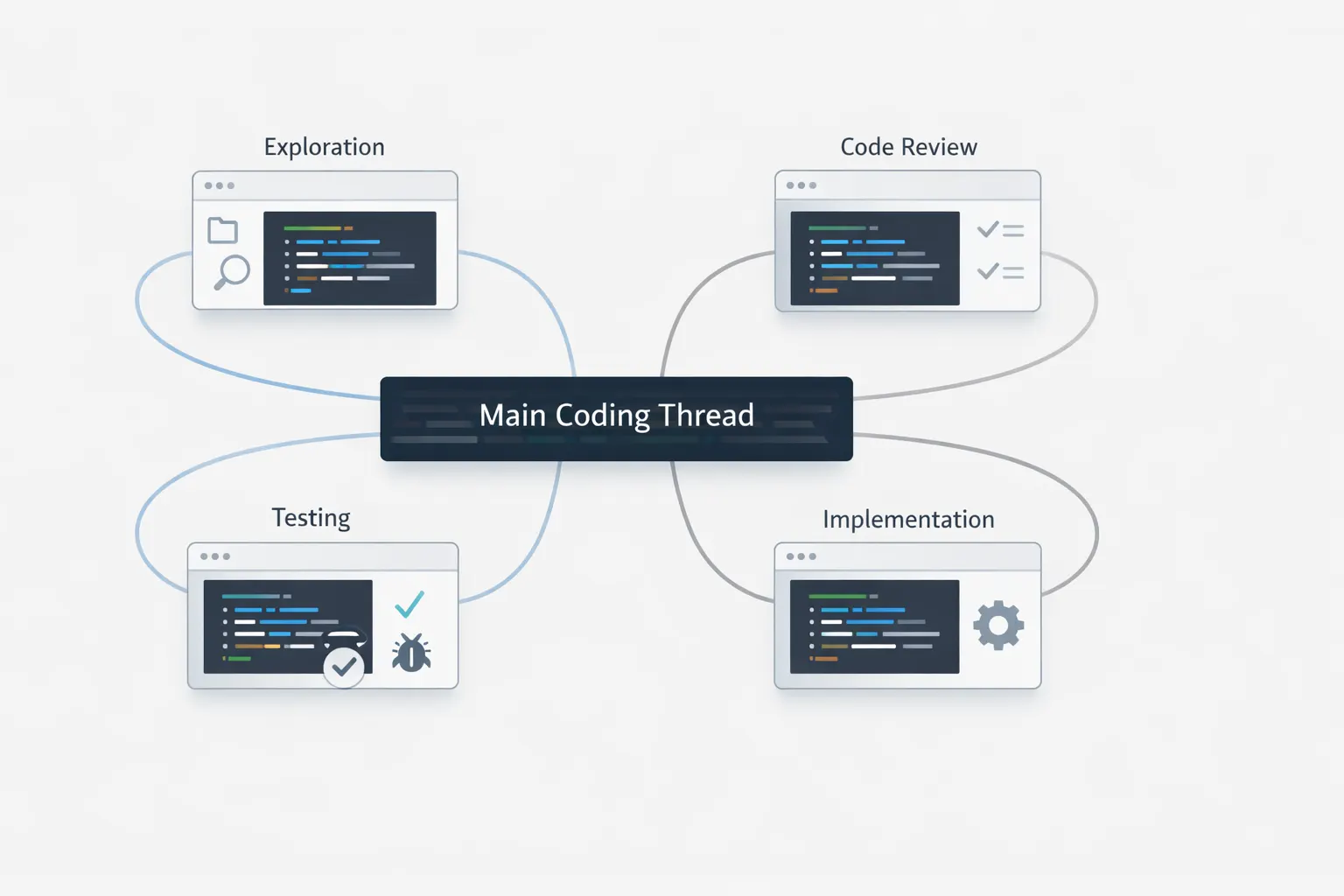
The core point is not that Codex can open more threads. The real change is that OpenAI has formalized a way to keep the main thread clean while parallel work happens elsewhere. That affects reliability, speed, and cost at the same time.
OpenAI says this quite directly in product language. In the Codex app announcement, the company says the app is built to manage multiple agents at once, run work in parallel, and handle long-running tasks. [4] This is not just a new switch in the UI. It is a change in how Codex expects larger engineering work to be split up.
The technical docs explain the practical reason even more clearly. Even with large context windows, the main conversation starts to degrade if you keep pushing logs, traces, intermediate hypotheses, and test noise into it. OpenAI names two concrete problems: context pollution and context rot. [1]
That also lines up with independent research. Chroma's Context Rot report shows that reliability declines as context grows, especially on harder tasks. [8] In practice, Codex subagents are OpenAI's product answer to that engineering reality.
Anthropic describes a very similar pattern from another angle in its Agent SDK materials: subagents are useful for parallelization and context management because they work in their own isolated context windows. [11] So this is not an OpenAI-only idea. It is becoming a common pattern for long-running agent workflows.
If you strip away the branding, the model is straightforward: one parent thread orchestrates, one or more child threads perform clearly bounded tasks, and then the parent pulls everything back into a final answer.
Keep the main thread for requirements and final judgment
The parent thread should carry the brief, constraints, architecture decisions, and final synthesis. OpenAI explicitly positions subagents as a way to keep the main thread focused on requirements, decisions, and end results. [1]
Give each child a narrow task
The docs use a pull request review example where Codex launches one agent per review dimension such as security, bugs, race conditions, flaky tests, and maintainability. That is exactly the right shape: one narrow task per child thread. [2]
Switch into child threads when you need to inspect or steer them
In the CLI, /agent lets you jump into the active agent thread, inspect what it is doing, and continue working there. This matters because delegation is not the same thing as blind trust. Critical decisions still need review. [6]
Let the parent thread consolidate the outcome
OpenAI says that after the requested work is done, Codex returns a consolidated response: parallel work below, one clean summary above. [2]
Summary
The parent thread should behave like a lead engineer. Subagents should behave like scoped specialists, not free-roaming copies of the lead.
This part matters because subagents no longer look like hidden internal magic. OpenAI has now documented both the built-in roles and the configuration surface around them.
Built-in roles already exist
OpenAI documents three built-in agents: default for general work, worker for execution-heavy implementation and fixes, and explorer for read-heavy codebase exploration. [2]
You can add your own agents
Custom agents live in ~/.codex/agents/ for personal use or .codex/agents/ at project level. Each one defines name, description, and developer_instructions, and can also override model, reasoning effort, sandbox mode, MCP servers, and skills. [2]
Parallelism is configurable
OpenAI documents [agents] settings such as max_threads, max_depth, and job_max_runtime_seconds. max_threads defaults to 6 and max_depth defaults to 1, so deep recursion is limited by default. [2]
Subagents inherit safety controls
Subagents inherit the current sandbox policy. Approval prompts can come from inactive threads, and deeper recursion is discouraged because it quickly increases token use, latency, and local resource load. [2]
Teams often get this wrong. On paid ChatGPT plans, the practical pain is usually not raw API token math. It is how quickly subagents burn through included limits or credits.
| Comparison point | What OpenAI says | What it means in practice |
|---|---|---|
| Subagent workflows | Consume more tokens than a comparable single-agent run. [1][2] | Parallel delegation is useful, but it is not free acceleration. Every child thread runs its own model and tool loop. |
| GPT-5.4-mini | Uses about 30% as much of your included limits as GPT-5.4 and can last about 3.3x longer before hitting limits. [3] | A strong default for lighter subagents: exploration, big-file review, support docs, and secondary analysis. |
| Local cost of GPT-5.4 | About 7 credits per local task on average. [7] | A strong parent-thread model, but expensive if you spray it across several child threads without thinking. |
| Local cost of GPT-5.4-mini | About 2 credits per local task on average. [7] | A much better fit when the subagent is doing support work, not final judgment. |
| Local and cloud cost of GPT-5.3-Codex | About 5 credits per local task and about 25 per cloud task on average. [7] | Still a strong option for truly hard software engineering work, especially when you want a coding-first profile instead of the broader GPT-5.4 profile. |
| Fast mode on GPT-5.4 | Roughly 1.5x speed and 2x credit rate. [5] | Useful for latency-sensitive work, but it accelerates credit burn on top of already more expensive subagent fan-out. |
Subagents are not a universal upgrade. They are a coordination tool.
Strong fit
Worth testing
Larger features where one child can take UI, another backend, and a third can prepare tests or migration notes. This only works when the boundaries are real and final judgment stays in the parent thread.
Often overkill
Small changes, single-file bugs, quick refactors, or any task where the real problem is not scale but clarity. In those cases delegation often costs more than doing the work in one thread.
High-risk zone
Parallel write-heavy work touching the same code surface. OpenAI directly warns that concurrent edits can create conflicts and increase coordination overhead. [1]
The most common mistake here is simple: people ask for subagents too vaguely. The working pattern is always the same: describe the split, give each child thread clear boundaries, and explain what exact output should come back to the main thread.
For PR review, a good prompt can look like this:
Spawn three subagents.
Agent 1: review security issues and secret handling.
Agent 2: review race conditions and concurrency risks.
Agent 3: review test gaps and flaky cases.
Return one merged summary with the most important findings first.For implementation work, it is important to separate ownership:
Use two subagents.
Agent 1 owns the API handler and schema changes.
Agent 2 owns the frontend form and validation wiring.
Do not edit the same files. Summarize conflicts before making final edits.For research-heavy tasks, it makes sense to request a cheaper child runtime immediately:
Spawn one explorer subagent per document.
Extract only the constraints, breaking changes, and migration risks.
Use `gpt-5.4-mini` for all child threads, then summarize in the main thread.Below is a practical set of recommendations for using subagents in Codex. The algorithm is fairly simple.
Ask for subagents explicitly and name the split
Do not just write investigate this. Write something like spawn one agent for security, one for race conditions, one for test flakiness, then summarize. This is the same request shape shown in the Codex docs. [2]
Keep the main thread short and clean
Let the parent thread hold scope, constraints, acceptance criteria, and final decisions. Noisy research belongs in child threads. [1]
Inspect child threads instead of blindly trusting the summary
Use /agent in the CLI if something looks suspicious or if a child result contains a critical decision that should not be accepted at face value. [6]
Do not push recursion deep
OpenAI did not set max_depth to 1 by default by accident. Deep recursive fan-out quickly increases token use, latency, and local resource pressure. [2]
Separate read-heavy from write-heavy delegation
The safest win is to parallelize analysis first. Move to parallel edits only when ownership boundaries are clear enough and conflicts are unlikely. [1]
The first mistakes are usually predictable. Almost all of them happen when subagents are treated like free extra labor instead of an orchestration tool.
Spawning subagents for a vague task. If the task has no clear boundaries, you just multiply confusion.
Parallelizing edits in the same files. The docs directly warn about conflicts and coordination overhead in write-heavy scenarios. [1]
Ignoring approval and sandbox inheritance. Child threads inherit the current sandbox policy, and approval prompts can come from inactive threads. [2]
Summary
Subagents work best when they remove noise, not when they multiply activity for the sake of activity.
No. OpenAI's docs explicitly say that Codex launches subagents only when you clearly ask for subagents or parallel agent work. [1][2]
OpenAI currently documents three built-in agents: `default`, `worker`, and `explorer`. `worker` is tuned for execution-heavy work, while `explorer` is tuned for read-heavy codebase research. [2]
Usually yes. OpenAI says workflows with subagents consume more tokens than similar one-thread scenarios because every child thread runs its own model and tool loop. On ChatGPT plans this is usually felt as faster consumption of included limits or credits. [1][2][7]
OpenAI's current logic is to start with `gpt-5.4` for the main task and use `gpt-5.4-mini` for lighter coding tasks or subagents. `gpt-5.3-codex` remains a strong option for difficult software engineering work. [3][5]
They work best on parallelizable, read-heavy work: exploration, tests, triage, summarization, and review. OpenAI explicitly recommends starting there and being much more careful with write-heavy parallel work. [1]
Not exactly. In practice usage almost always goes up, but OpenAI does not publish one fixed multiplier for every plan and every scenario. The real effect depends on model choice, task size, context volume, local versus cloud execution, and how many child threads you spawn. [1][2][7]
This article is based on current OpenAI documentation and product pages for Codex, pricing, changelog, and speed, plus external research on context degradation and Anthropic materials on the Agent SDK.
Related Articles
AI Assistant Development Cost in 2026: RAG Chatbots, CRM Integrations, Guardrails, and Support
A practical buyer guide to AI assistant development cost in 2026: prototypes, RAG chatbots, knowledge-base assistants, CRM and website integrations, guardrails, evaluations, monitoring, and support.
AI for landing page development: where it speeds up launches and where it hurts conversion
A practical research piece on using AI for landing page development: v0, Webflow AI, Builder.io, Framer-like builders, UX generation, copy, SEO, personalization, A/B testing, template risk, accessibility, security and technical debt.
AI SEO / GEO in 2026: Your Next Customers Aren’t Humans — They’re Agents
Search is shifting from clicks to answers. Bots and AI agents crawl, cite, recommend, and increasingly buy. Learn what AI SEO / GEO means, why classic SEO is no longer enough, and how PAS7 Studio helps brands win visibility in the agentic web.
The most powerful Apple chip yet? M5 Pro and M5 Max are breaking records
A data-backed March 2026 analysis of Apple M5 Pro and M5 Max. We break down why these chips can credibly be called Apple's most powerful pro laptop silicon, how they compare with M4 Pro, M4 Max, M1 Pro, M1 Max, and how they stack up against Intel and AMD laptop rivals.
Professional development for your business
We create modern web solutions and bots for businesses. Learn how we can help you achieve your goals.