Perché Timber accelera così tanto i modelli ML: analisi pratica
Un'analisi pratica del compilatore Timber. Basandoci sul repository stesso, spieghiamo perché Timber può portare la classical ML inference quasi nel territorio dei microsecondi e da dove arriva davvero questo guadagno.
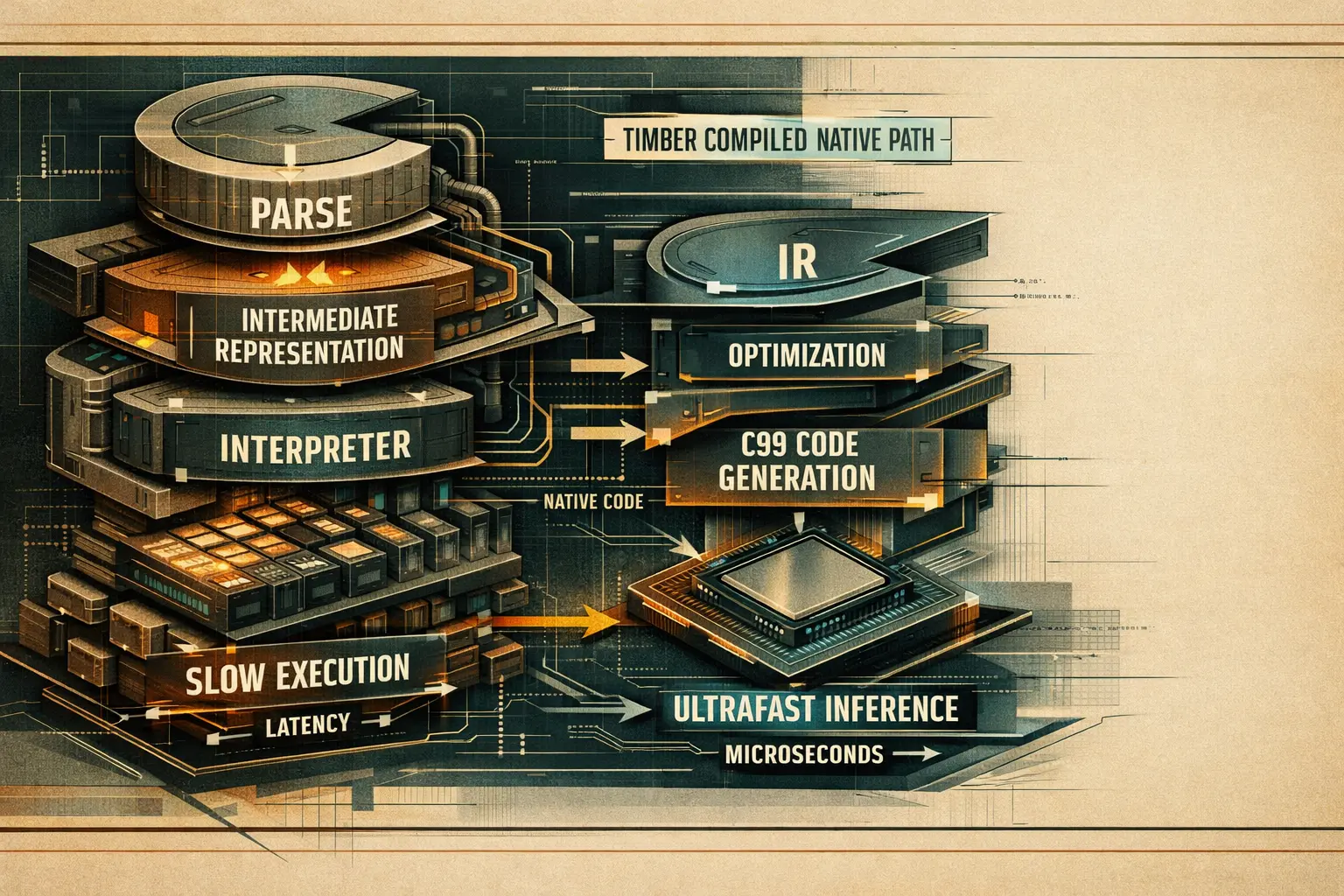
Ecco cosa conviene capire subito.
• Timber non è un acceleratore per LLM. È un compilatore per classical ML inference. [4][5]
• Il guadagno di velocità nasce da un'idea semplice eseguita bene: parsare il modello addestrato una sola volta, ottimizzare il grafo una sola volta, generare native C una sola volta e poi rimuovere per sempre il Python-heavy hot path. [4][5][6][7]
• Il loro benchmark headline è forte: ~2 microsecondi di single-sample inference, ~336x più veloce di Python XGBoost e un artefatto compilato di circa ~48 KB nel setup di riferimento. [4]
• Le ragioni a livello di repository sono concrete: dead leaf elimination, threshold quantization, branch sorting, pipeline fusion, rappresentazione flat array degli alberi, assenza di heap allocation, assenza di recursion, contiguous float32 inputs e chiamate
ctypesdirette nel compiled code. [5][6][7]• Il caveat importante è questo: il benchmark misura in-process single-sample latency, non un end-to-end network serving completo. I numeri sono reali per quel setup, ma non sono una promessa universale di production. [8][9]
La prima correzione importante è concettuale. Timber non è solo un altro Python package che incapsula XGBoost e lo fa andare più veloce. Il repository lo presenta chiaramente come un multi-stage compiler per modelli classical ML. Tra gli input supportati ci sono XGBoost, LightGBM, scikit-learn, CatBoost e ONNX per trees, linear models e SVMs. L'output è un self-contained C99 inference artifact senza runtime dependencies. [4][5]
Questa architettura conta perché cambia il punto in cui vive il costo. Una grossa parte della latenza nei classici Python model-serving stack non è la matematica del modello in sé. È la combinazione di Python runtime overhead, framework abstractions, object dispatch, memory layout sfavorevole e strati generici di serving intorno al modello. Timber attacca tutto questo stack compilando il modello in un execution path più semplice. [4][5][7]
Il proprio high-level flow nel repository è esplicito: frontend parser -> Timber IR -> optimizer passes -> backend emitter -> native compile -> thin serve path. È un approccio molto più aggressivo del semplice export verso un altro runtime. [5]
L'architettura di Timber è costruita intenzionalmente come un compilatore. Per questo il profilo di latenza cambia così tanto. [5]
Screenshot della sezione what-timber-isNon c'è un solo trucco magico. Il risultato nasce da più scelte che eliminano lavoro a runtime strato dopo strato.
1. Timber elimina i branch inutili prima del primo predict
L'optimizer pipeline esegue passes come dead leaf elimination e constant feature detection. Se entrambi i rami di un node producono lo stesso risultato, il node viene trasformato in un leaf. Se calibration data mostrano che una feature è di fatto costante, Timber può saltare direttamente al deterministic child. Meno branching significa meno lavoro in inference. [6]
2. Timber incorpora il preprocessing direttamente nel modello
Uno dei passes più importanti è pipeline fusion. Se uno scaler stage si trova subito prima di un tree ensemble, Timber riscrive le thresholds e rimuove totalmente lo scaler computation dal runtime. È un'ottimizzazione molto forte perché elimina un intero preprocessing stage, non solo qualche istruzione. [5][6]
3. Timber adatta la forma dei branch alla CPU
Quando sono disponibili calibration data, Timber può riordinare left e right children in modo che il path più frequente diventi la branch direction naturale. Sulla carta sembra un dettaglio, ma proprio negli hot inference loops questi guadagni di branch prediction si accumulano bene. [5][6]
4. Timber restringe i dati dove è sicuro farlo
Threshold quantization prova a fare downcast delle float64 thresholds a float32, ma solo quando calibration data mostrano che questo non cambia la split decision. Così si riduce la dimensione del modello e si può migliorare il cache behavior senza falsare le predictions. [5][6]
Più lavoro prima
Timber spende risorse una sola volta in parse e optimization così inference deve fare meno lavoro. [5][6]
Flat static arrays
I nodes sono memorizzati come array data e non come pointer-heavy heap structures. Questo migliora la locality e rimuove allocation overhead. [5]
Senza recursion
Il traversal generato è iterativo e bounded, quindi più economico e più sicuro per tight loops ed embedded targets. [5]
Ponte ctypes sottile
I numpy arrays vengono convertiti in contiguous float32 e passati come raw pointers direttamente nel compiled code. [7]
Questo repository merita di essere letto perché la performance-story qui non è solo marketing. L'orchestrazione dell'optimizer in timber/optimizer/pipeline.py rende esplicita la sequenza: dead_leaf_elimination, constant_feature_detection, threshold_quantization, opzionale frequency_branch_sort, pipeline_fusion e poi vectorization_analysis. L'ordine è logico. Prima si semplifica la struttura dell'albero, poi si comprime la rappresentazione, poi si migliora la branch direction e solo dopo si fondono gli stages. [6]
Il runtime path in timber/runtime/predictor.py è altrettanto rivelatore. Gli inputs vengono convertiti in contiguous float32 numpy arrays. Gli outputs vengono preallocati. Il predictor ottiene raw pointers con .ctypes.data_as(...) e chiama direttamente timber_infer o timber_infer_single. Nel hot path c'è pochissima Python object choreography oltre al marshaling iniziale degli array. [7]
Un breve estratto del flusso è questo:
X = np.ascontiguousarray(X, dtype=np.float32)
outputs = np.zeros((n_samples, self.n_outputs), dtype=np.float32)
inputs_ptr = X.ctypes.data_as(ctypes.POINTER(ctypes.c_float))
outputs_ptr = outputs.ctypes.data_as(ctypes.POINTER(ctypes.c_float))
rc = self._lib.timber_infer(inputs_ptr, n_samples, outputs_ptr, self._ctx)È un percorso molto diverso dal restare dentro un Python ML framework completo per ogni prediction. Il punto non è solo il native code. Il punto è native code più un call chain molto più sottile. [7]
La documentation di architecture dice anche esplicitamente che il C generato usa static const arrays, non ha heap allocation, non usa recursion e adotta double-precision accumulation dove serve per la numerical stability. Timber quindi non scambia velocità con scorciatoie evidenti sulla correttezza. [5]
Il repository fa una cosa che molti progetti performance saltano. Espone apertamente la benchmark methodology nel codice. Il benchmark runner allena un reference XGBoost classifier su sklearn.datasets.load_breast_cancer, usando 50 trees, max depth 4, 30 features, 1.000 warmup iterations e 10.000 timed single-sample predictions. Vengono misurati mean, p50, p95, p99 e throughput in microsecondi. [8][9]
| Runtime | Headline dalle Timber docs | Cosa significa davvero |
|---|---|---|
| Timber native C | ~2 microsecondi | In-process, single-sample inference tramite compiled native code. [4][8][9] |
| Python XGBoost | ~670 microsecondi | Python baseline nello stesso benchmark script. [4][9] |
| Treelite | ~10 a 30 microsecondi | Compiled baseline opzionale se installato. [4][8] |
| ONNX Runtime | ~80 a 150 microsecondi | Baseline opzionale nelle benchmark docs. [4][8] |
| HTTP serving overhead | Non incluso nell'headline | Il README dice chiaramente che il network overhead aggiunge circa 50 a 200 microsecondi a seconda dello stack. [4] |
Proprio per l'ultima riga un lettore serio non dovrebbe esagerare. Il benchmark di Timber resta molto utile perché isola l'inference engine. Ma se poi il modello viene messo dietro un vero API gateway, JSON serialization, auth, queue e cross-process hops, il latency budget finale cambia. [4][8]
L'architettura è forte, ma non è una magia universale per qualsiasi stack ML.
Dove il fit è molto buono
Dove non è un fit diretto
La disciplina dei benchmark conta ancora
No. Il repository è focalizzato su famiglie classical ML come tree ensembles, linear models e SVMs. Tutta la logica di ottimizzazione di questo articolo è legata proprio a queste, non a qualsiasi modello. [4][5]
No, se la si legge nel suo contesto. Il repository documenta un reference benchmark in cui la native inference di Timber è circa 336 volte più veloce di Python XGBoost. Il punto importante è che qui si misura in-process single-sample latency e non la network request latency completa. [4][8][9]
La ragione più importante è che Timber sposta lavoro dal runtime al compile time. Parsifica il modello nel proprio IR, esegue optimizer passes, genera C99 e poi espone un native inference path molto più sottile. [5][6][7]
Bisogna benchmarkare il proprio request path reale e non solo isolated model inference. Misurate in-process latency, network overhead, serialization cost, batch shape e concurrency behavior sul vostro hardware. Anche il repository raccomanda di pubblicare metodologia e dettagli hardware insieme ai numeri. [8][9]
Primary sources e file del repository usati per la parte fattuale di questo articolo. Il link Threads sotto resta come contesto per il tono, non come base probatoria per le affermazioni tecniche.
Articoli correlati
AI SEO / GEO nel 2026: i tuoi prossimi clienti non sono umani — sono agenti
La ricerca sta passando dai click alle risposte. Bot e agenti AI scansionano, citano, raccomandano e sempre più spesso acquistano. Scopri cosa significa AI SEO / GEO, perché la SEO classica non basta più e come PAS7 Studio aiuta i brand a vincere visibilità nel web “agentico”.
Il chip Apple più potente? M5 Pro e M5 Max battono i record
Analisi di Apple M5 Pro e M5 Max aggiornata a marzo 2026. Spieghiamo perché questi chip possono essere considerati i SoC professionali per notebook più potenti di Apple, come si posizionano contro M4 Pro, M4 Max, M1 Pro, M1 Max e cosa mostrano rispetto ai concorrenti Intel e AMD.
Tag automatici e ricerca per link salvati
Integra con GDrive/S3/Notion per tag automatici e ricerca veloce tramite API di ricerca
Sviluppo di bot e servizi di automazione
Sviluppo professionale di bot Telegram e automazione dei processi aziendali: chatbot, assistenti AI, integrazioni CRM, automazione dei flussi di lavoro.
Sviluppo professionale per la tua attività
Creiamo soluzioni web moderne e bot per le aziende. Scopri come possiamo aiutarti a raggiungere i tuoi obiettivi.