Zašto Timber toliko ubrzava ML modele: praktična analiza
Praktična analiza Timber kompajlera. Na temelju samog repozitorija objašnjavamo zašto Timber može spustiti classical ML inference gotovo do mikrosekundi i odakle taj dobitak stvarno dolazi.
Ovo vrijedi razumjeti odmah.
• Timber nije akcelerator za LLM-ove. To je kompajler za classical ML inference. [4][5]
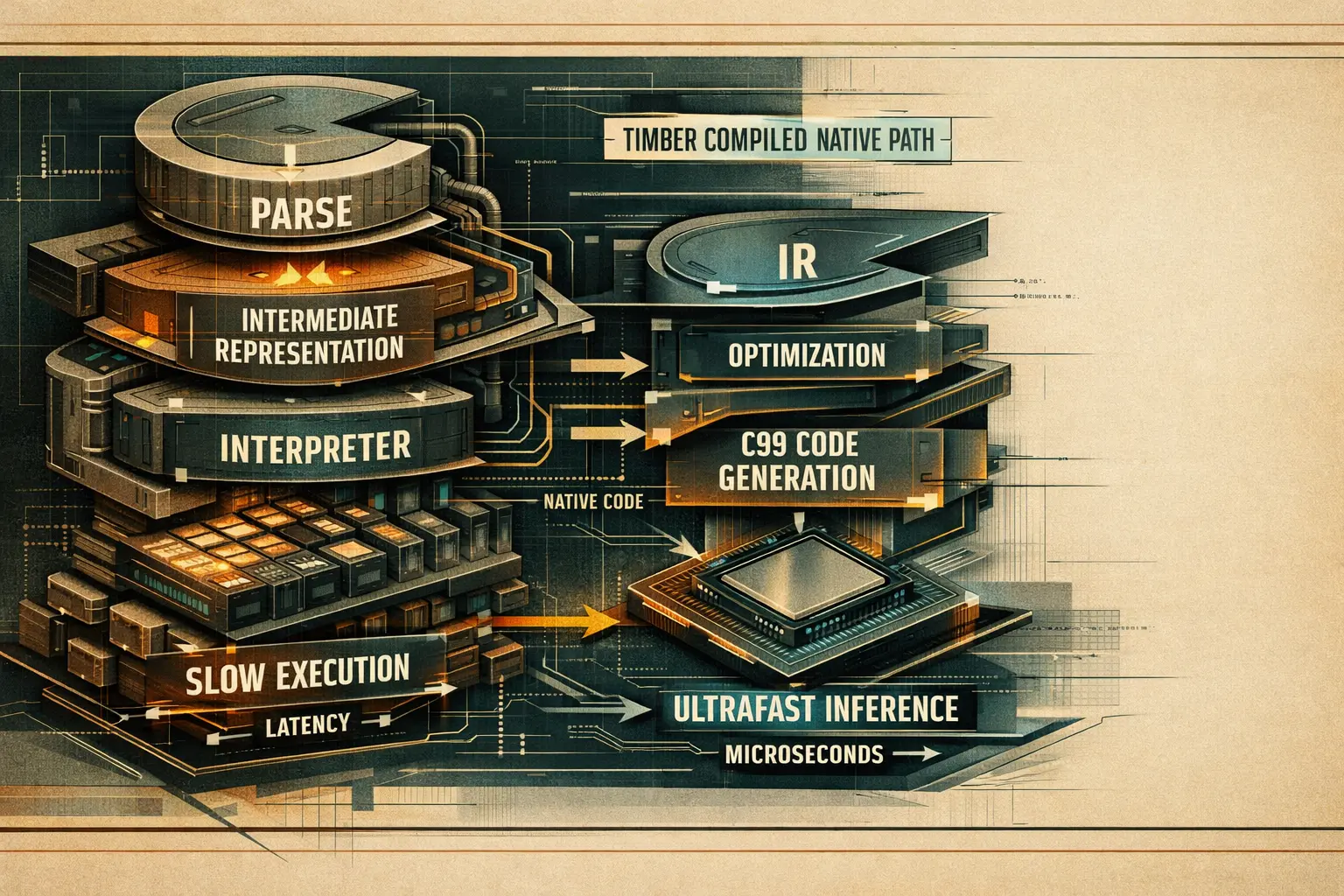
• Dobitak u brzini temelji se na jednostavnoj ideji dobro provedenoj u praksi: jednom parsirati istrenirani model, jednom optimizirati graf, jednom generirati native C i zatim trajno ukloniti Python-heavy hot path. [4][5][6][7]
• Njihov benchmark headline je jak: ~2 mikrosekunde za single-sample inference, ~336x brže od Python XGBoosta i kompajlirani artefakt od oko ~48 KB u referentnom setupu. [4]
• Razlozi na razini repozitorija su vrlo konkretni: dead leaf elimination, threshold quantization, branch sorting, pipeline fusion, flat array prikaz stabala, bez heap allocation, bez recursion, contiguous float32 inputs i direktni
ctypespozivi prema compiled codeu. [5][6][7]• Važan caveat je sljedeći: benchmark mjeri in-process single-sample latency, a ne puni end-to-end network serving. Brojke su realne za taj setup, ali nisu univerzalno production obećanje. [8][9]
Prva važna korekcija ovdje je konceptualna. Timber nije samo još jedan Python package koji obavija XGBoost i nekako ga tjera da radi brže. Repo ga jasno predstavlja kao multi-stage compiler za classical ML modele. Podržani ulazi uključuju XGBoost, LightGBM, scikit-learn, CatBoost i ONNX za trees, linear models i SVMs. Na izlazu dobivamo self-contained C99 inference artifact bez runtime dependencies. [4][5]
Ta arhitektura je važna jer mijenja mjesto na kojem nastaje trošak. Velik dio latencije u tipičnim Python model-serving stackovima nije sama matematika modela. To je kombinacija Python runtime overheada, framework abstractions, object dispatcha, nepovoljnog memory layouta i općih serving slojeva oko modela. Timber napada cijeli taj stack tako što model kompajlira u jednostavniji execution path. [4][5][7]
Njihov vlastiti high-level flow u repozitoriju je eksplicitan: frontend parser -> Timber IR -> optimizer passes -> backend emitter -> native compile -> thin serve path. To je puno agresivniji pristup od pukog izvoza u još jedan runtime. [5]
Timberova arhitektura je namjerno izgrađena kao kompajler. Upravo zato se latency profil tako snažno mijenja. [5]
Snimka zaslona sekcije what-timber-isOvdje nema jednog čarobnog trika. Rezultat dolazi iz više odluka koje uklanjaju runtime posao sloj po sloj.
1. Timber briše nepotrebne grane prije prvog predict poziva
Optimizer pipeline pokreće passes poput dead leaf elimination i constant feature detection. Ako obje grane nekog nodea završavaju istim rezultatom, node postaje leaf. Ako calibration data pokažu da je neka feature praktično konstantna, Timber može odmah otići u deterministic child. Manje branching-a znači manje posla tijekom inferencea. [6]
2. Timber ugrađuje preprocessing izravno u model
Jedan od najvažnijih passes je pipeline fusion. Ako scaler stage stoji neposredno prije tree ensemblea, Timber prepisuje thresholds i potpuno uklanja scaler computation iz runtimea. To je neuobičajeno jaka optimizacija jer briše cijeli preprocessing stage, a ne samo nekoliko instrukcija. [5][6]
3. Timber prilagođava oblik grana CPU-u
Kad su calibration data dostupni, Timber može preurediti left i right children tako da češći path postane prirodni smjer brancha. Na papiru to izgleda kao sitnica, ali upravo se u hot inference loops takvi dobici od branch predictiona dobro zbrajaju. [5][6]
4. Timber sužava podatke tamo gdje je to sigurno
Threshold quantization pokušava downcastati float64 thresholds na float32, ali samo kada calibration data pokažu da to ne mijenja split decision. Time se smanjuje veličina modela i može se poboljšati cache behavior bez tihog iskrivljavanja predictions. [5][6]
Više posla unaprijed
Timber ulaže trud jednom tijekom parse i optimization faze kako bi inference kasnije radio manje. [5][6]
Ravni statični nizovi
Nodes se spremaju kao array data umjesto kao pointer-heavy heap structures. To poboljšava locality i uklanja allocation overhead. [5]
Bez recursion
Generirani traversal je iterativan i bounded, što je jeftinije i sigurnije za tight loops i embedded targets. [5]
Tanak ctypes most
Numpy nizovi se pretvaraju u contiguous float32 i predaju kao raw pointers izravno u compiled code. [7]
Ovaj repo vrijedi čitati jer performance priča ovdje nije samo marketinška. Orkestracija optimizatora u timber/optimizer/pipeline.py jasno pokazuje redoslijed: dead_leaf_elimination, constant_feature_detection, threshold_quantization, opcionalni frequency_branch_sort, pipeline_fusion, a zatim vectorization_analysis. Redoslijed je logičan. Prvo se pojednostavljuje struktura stabla, zatim stišće prikaz, zatim popravlja branch direction i tek onda spajaju stages. [6]
Runtime path u timber/runtime/predictor.py jednako je rječit. Inputs se pretvaraju u contiguous float32 numpy arrays. Outputs se unaprijed alociraju. Predictor dobiva raw pointers putem .ctypes.data_as(...) i izravno poziva timber_infer ili timber_infer_single. U hot pathu gotovo da nema Python object choreography osim jednokratnog marshalinga nizova. [7]
Kratki isječak tog toka izgleda ovako:
X = np.ascontiguousarray(X, dtype=np.float32)
outputs = np.zeros((n_samples, self.n_outputs), dtype=np.float32)
inputs_ptr = X.ctypes.data_as(ctypes.POINTER(ctypes.c_float))
outputs_ptr = outputs.ctypes.data_as(ctypes.POINTER(ctypes.c_float))
rc = self._lib.timber_infer(inputs_ptr, n_samples, outputs_ptr, self._ctx)To je sasvim drugačiji put od ostajanja unutar punog Python ML frameworka za svaki pojedini prediction. Poanta nije samo native code. Poanta je native code plus znatno tanji call chain. [7]
Architecture documentation također izričito kaže da generirani C koristi static const arrays, nema heap allocation, nema recursion i koristi double-precision accumulation tamo gdje je to potrebno za numerical stability. Dakle, Timber ne mijenja brzinu za očite kompromise u točnosti. [5]
Repo radi nešto što mnogi performance projekti preskaču. Benchmark metodologija otvoreno je prikazana u kodu. Benchmark runner trenira reference XGBoost classifier na sklearn.datasets.load_breast_cancer, koristeći 50 trees, max depth 4, 30 features, 1.000 warmup iterations i 10.000 timed single-sample predictions. Mjere se mean, p50, p95, p99 i throughput u mikrosekundama. [8][9]
| Runtime | Headline iz Timber docs | Što to stvarno znači |
|---|---|---|
| Timber native C | ~2 mikrosekunde | In-process, single-sample inference kroz compiled native code. [4][8][9] |
| Python XGBoost | ~670 mikrosekundi | Python baseline u istom benchmark scriptu. [4][9] |
| Treelite | ~10 do 30 mikrosekundi | Opcionalni compiled baseline ako je instaliran. [4][8] |
| ONNX Runtime | ~80 do 150 mikrosekundi | Opcionalni baseline u benchmark docs. [4][8] |
| HTTP serving overhead | Nije uključen u headline | README izričito kaže da network overhead dodaje otprilike 50 do 200 mikrosekundi ovisno o stacku. [4] |
Upravo zbog zadnjeg retka ozbiljan čitatelj ovdje ne bi smio pretjerivati. Timberov benchmark je i dalje vrlo koristan jer izolira inference engine. Ali ako model kasnije stavite iza stvarnog API gatewaya, JSON serializationa, autha, redova i cross-process hops, konačni latency budget bit će drukčiji. [4][8]
Arhitektura je jaka, ali nije univerzalna magija za svaki ML stack.
Gdje je pristup vrlo dobar
Gdje nije izravan fit
Disciplina benchmarka i dalje je važna
Ne. Repo je fokusiran na classical ML obitelji poput tree ensembles, linear models i SVMs. Cijela logika optimizacije u ovom članku vezana je upravo uz njih, a ne uz bilo koji model. [4][5]
Ne, ako se broj čita u vlastitom kontekstu. Repo dokumentira reference benchmark u kojem je Timber native inference oko 336 puta brža od Python XGBoosta. Važna nijansa je da se ovdje mjeri in-process single-sample latency, a ne puna network request latencija. [4][8][9]
Najvažniji razlog je to što Timber premješta posao iz runtimea u compile time. Parsira model u vlastiti IR, pokreće optimizer passes, generira C99 i zatim izlaže mnogo tanji native inference path. [5][6][7]
Treba benchmarkirati stvarni request path, a ne samo isolated model inference. Mjerite in-process latency, network overhead, serialization cost, batch shape i concurrency behavior na vlastitom hardveru. I sam repo preporučuje objaviti metodologiju i hardware details zajedno s brojkama. [8][9]
Primary sources i datoteke repozitorija korištene za činjenični dio ovog članka. Threads link ispod ostaje kao kontekst za ton, a ne kao dokazna baza za tehničke tvrdnje.
Povezani članci
AI SEO / GEO u 2026: vaši sljedeći kupci nisu ljudi — nego agenti
Pretraživanje se pomiče s klikova na odgovore. Botovi i AI agenti pretražuju, citiraju, preporučuju i sve češće kupuju. Saznajte što znači AI SEO / GEO, zašto klasični SEO više nije dovoljan i kako PAS7 Studio pomaže brendovima pobijediti u agentičkom webu.
Najmoćniji Apple čip? M5 Pro i M5 Max ruše rekorde
Analiza Apple M5 Pro i M5 Max čipova u ožujku 2026. Objašnjavamo zašto se ovi čipovi mogu smatrati najjačim profesionalnim laptop SoC-ovima koje je Apple dosad napravio, kako izgledaju protiv M4 Pro, M4 Max, M1 Pro, M1 Max i što pokazuju u usporedbi s aktualnim Intel i AMD konkurentima.
Automatsko označavanje i pretraga spremljenih linkova
Integracija s GDrive/S3/Notion za automatsko označavanje i brzu pretragu putem search API-ja
Razvoj botova i usluge automatizacije
Profesionalni razvoj Telegram botova i automatizacija poslovnih procesa: chatbotovi, AI asistenti, CRM integracije, automatizacija radnih tijekova.
Profesionalni razvoj za vaše poslovanje
Kreiramo moderne web rješenja i botove za poduzeća. Saznajte kako vam možemo pomoći u postizanju ciljeva.