Was steckt wirklich in einem KI-Agenten
Eine praktische Analyse dessen, was 2026 tatsächlich in einem KI-Agenten steckt: Entscheidungszyklus, Tools, Speicher, Checkpoints, Richtlinien, Freigaben, Tracing, Evals und die Grenze zwischen Workflow und vollständiger Agent-Runtime.
Der häufigste Fehler ist simpel: Man sieht ein Modell mit Tool Calling und nennt es sofort einen Agenten. Für ein Demo reicht das. Für ein System, das Zustand halten, sich von fehlerhaften Schritten erholen, Freigaben einholen und nach einem Fehler eine klare Spur hinterlassen muss, reicht es nicht.
Die Verwirrung beginnt damit, dass verschiedene Communities mit dem Wort Agent unterschiedliche Schichten desselben Systems meinen. Für die einen ist ein Agent jede Schleife, die Tools aufrufen kann. Für die anderen ist ein Agent bereits eine gesteuerte Runtime mit Richtlinien, Freigaben, Speicher und Observability. Beide beschreiben etwas Reales, aber eben auf unterschiedlicher Ebene.
Der DOU-Artikel und die Diskussion zeigen diese Trennung ziemlich gut. Der Artikel selbst erklärt den Basiszyklus sauber, in den Kommentaren taucht aber ein wichtiger Einwand auf: Ein ernsthafter Agent ist nicht einfach 'ein Gehirn in einer Schleife', sondern eine verwaltete Ausführungseinheit mit klaren operativen Grenzen. [1] Genau deshalb fühlen sich einfache Demos und Production-Systeme wie zwei verschiedene Softwareklassen an.
Anthropic bleibt zuletzt recht nah an einer einfachen Untergrenze: Ein Agent ist ein LLM, das Tools autonom in einer Schleife nutzt. [2] Das ist eine nützliche Basis. Sie trennt den Agenten von einer One-shot Completion. Aber sie beschreibt noch immer nicht das gesamte System.
Praktisch kann man es so fassen: Der Agent beginnt mit der Schleife, das wirklich nützliche Produkt beginnt mit der Runtime um diese Schleife herum. Sobald ein System suchen, lesen, schreiben, Code ausführen und wiederholt APIs aufrufen kann, verlagern sich die Hauptprobleme von der Generierungsqualität zu Kontrolle, Zustand und Fehlermanagement.
Im Zentrum des Systems steht ein wiederholter Zyklus. Eine Anfrage oder ein Ziel kommt herein. Das Modell liest den aktuellen Kontext. Es wählt die nächste Aktion. Diese Aktion kann eine normale Antwort, ein strukturierter Output oder ein Tool-Aufruf sein. Danach liefert die Umgebung eine neue Beobachtung zurück und der Zyklus wiederholt sich, bis eine Stop-Bedingung erfüllt ist.
Genau diesen Teil sehen die meisten Menschen zuerst. Er ist auch am einfachsten zu erklären. In Anthropics Material zum Agent SDK wird der typische Feedback Loop als 'context sammeln -> handeln -> Ergebnis prüfen -> wiederholen' beschrieben. [3] Für viele Production-Agenten ist das eine sehr treffende vereinfachte Darstellung, auch wenn die Runtime um die Schleife herum später viel komplexer wird.
Eine minimale Implementierung kann tatsächlich kurz sein. Damit hat der DOU-Text recht. Eine Basisschleife mit Tools, Prompt-State und einem Schrittlimit passt in relativ wenig Code. [1] Kurzer Code bedeutet aber nicht automatisch ein einfaches System. Es bedeutet meist nur, dass Komplexität in getrennte Services, Tool-Verträge, Speicherlogik und operative Schutzmechanismen verschoben wurde.
Hier ist eine bewusst reduzierte Version des Mechanismus. Sie ist absichtlich klein gehalten, damit die Grenzen klar bleiben:
messages = [system_prompt, user_request]
steps = 0
while steps < MAX_STEPS:
response = model.run(messages=messages, tools=TOOLS)
if response.final_output:
return response.final_output
if response.tool_calls:
for call in response.tool_calls:
result = run_tool(call.name, call.arguments)
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": serialize(result),
})
else:
messages.append(response.message)
steps += 1
raise RuntimeError("Agent exceeded max steps")Wenn man nur diese Schleife liest, versteht man, wo ein Agent beginnt. Es reicht aber noch nicht, um zu erklären, warum ein Agent stabil bleibt, ein anderer teuer wird und ein dritter still Risiken ansammelt, bis er unter realer Nutzung bricht.
Takeaway
Die Schleife erklärt das Verhalten eines Agenten. Sie erklärt für sich genommen noch nicht Qualität, Kosten oder Sicherheit.
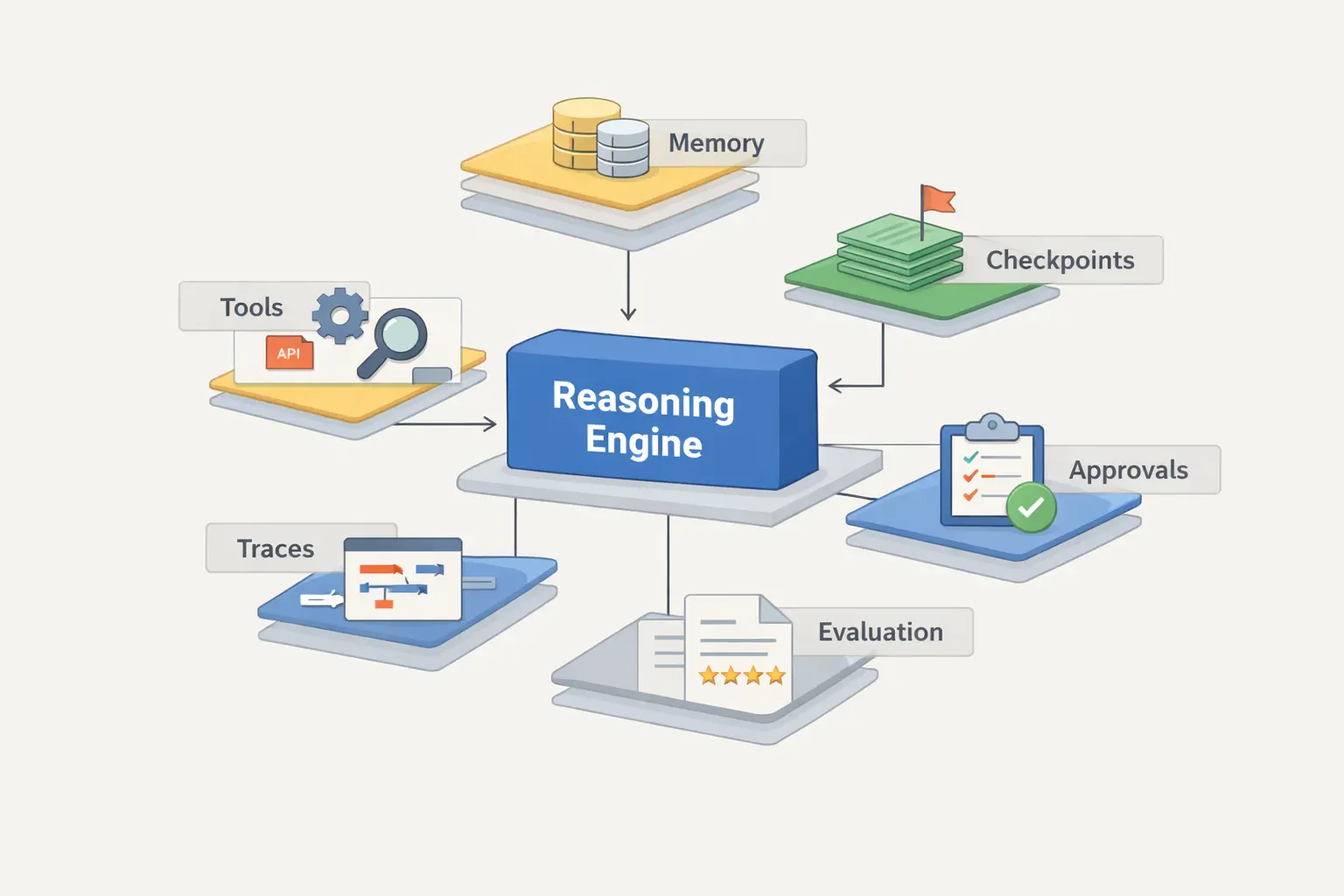
Sobald man über Spielzeug-Agenten hinausgeht, ist die zentrale Frage nicht mehr, ob das Modell ein Tool aufrufen kann. Die eigentliche Frage lautet dann: Nach welchen Regeln darf es überhaupt handeln, welchen Zustand trägt es mit, was wird gespeichert, was braucht eine Freigabe und wie untersucht man einen schlechten Lauf nach einem Fehler.
OpenAIs Release zum Building Agents ist hier nützlich, weil es eben nicht nur als Thema von Model Calls gerahmt wird. Im Fokus stehen auch Built-in Tools, Orchestration und Integrated Observability für das Tracing von Workflow-Ausführung. [4] Das ist ein wichtiges Signal: Selbst Plattformanbieter rahmen Agentenbau inzwischen als Runtime-Problem und nicht bloß als Prompt-Thema.
Dasselbe Muster sieht man in Framework-Dokumentation. LangGraphs Persistence-Doku spricht über Checkpoints, Threads, Replay, Time Travel und Fault Tolerance. [6] Microsoft Agent Framework stellt Observability in den Mittelpunkt und führt Traces, Logs und Metrics über OpenTelemetry. [7] Das sind keine Bonus-Funktionen. Es sind die Bausteine, mit denen Teams lang laufendes Verhalten debuggen, wieder aufnehmen, prüfen und kontrollieren können.
Ein brauchbares Arbeitsmodell sieht so aus: Oben stehen Ziel und Berechtigungen, darunter die Planning Policy, dann der Zugriff auf Tools, dann Zustand und Speicher und darum herum eine Control Plane mit Tracing, Evals, Approvals und Rollback. Das Modell ist wichtig, aber es ist immer noch nur eine Schicht in der ganzen Struktur.
Takeaway
Je mehr Freiheit ein Agent bekommt, desto mehr Runtime-Gerüst muss um das Modell herum existieren.
Diese Trennung ist wichtig, weil Teams Agent-Infrastruktur oft in Probleme ziehen, die in Wirklichkeit nur Workflows sind. Das Ergebnis ist ein System, das teurer und schwerer zu testen ist, ohne genug zusätzliche Fähigkeiten zu liefern, um den Aufwand zu rechtfertigen.
Workflow
Agent runtime
Schlechte Mitte
Das System wirkt autonom, hat aber keine klaren Berechtigungen, keine Stop-Regeln, keine replaybare Historie und keine verlässliche Review-Fläche. Genau dort landen Teams bei teuren Demos, denen man schwer vertrauen und noch schwerer debuggen kann.
Faustregel
Wenn der Pfad bereits bekannt ist, beginnen Sie mit einem Workflow. Greifen Sie erst dann zu einem Agenten, wenn der Weg selbst während der Ausführung entdeckt werden muss.
| Comparison point | Was es meist bedeutet | Warum es wichtig ist |
|---|---|---|
| Aktuelles Context Window | Der aktive Prompt, aktuelle Nachrichten, Tool-Ergebnisse und der Arbeitszustand des laufenden Runs. | Genau das bricht am schnellsten, wenn ein Agent zu lange loopt oder zu viel verrauschten Tool-Output ansammelt. [1][5][9] |
| Checkpoints oder Thread State | Gespeicherte Ausführungssnapshots, aus denen ein Run später fortgesetzt, replayed oder untersucht werden kann. | Das ist die Grundlage dafür, dass menschliche Freigaben, Unterbrechungen, Debugging und Wiederherstellung nach Fehlern praktisch werden. [6] |
| Long-term Memory Store | Langlebigere Fakten, Nutzerpräferenzen oder Zusammenfassungen, die außerhalb des aktuellen Context Windows gespeichert werden. | Nützlich, wenn ein Agent Kontinuität zwischen Sitzungen braucht, aber riskant, wenn die Speicherpolitik vage bleibt oder Daten veralten. [5][6] |
Diese Ebene macht aus einem autonomen Demo ein technisches System. Fehlt sie, wird Production-Nutzung schnell schwierig.
Keine Freigabegrenze. Wenn ein Agent Side Effects ohne menschliches Review auslösen kann, wo Review notwendig wäre, wird das System schnell fragil.
Keine Eval-Disziplin. Anthropic formuliert es ziemlich klar: Capability-Evals, Regression-Suites, Transcript-Review und kontinuierliche Prüfungen sind nicht optional, sobald das System wichtig wird. [8]
Kein Rollback- oder Recovery-Pfad. Wenn ein Schritt mitten im Prozess scheitert und das System nicht von einem bekannten Zustand aus fortsetzen oder replayen kann, bleibt der Operator faktisch blind. [6]
Kurz gesagt
Je mehr Autonomie Sie erlauben, desto mehr Control Plane braucht es rundherum. Sonst ist das System nur im unbrauchbarsten Sinn agentisch: Es handelt selbstständig, aber niemand kann es sauber steuern.
Wenn Sie nur einen Abschnitt in ein Architecture Review mitnehmen wollen, dann diesen.
Fragen Sie zuerst, wo der Pfad tatsächlich entschieden wird.
Wenn die Route überwiegend im Code festliegt, nennen Sie es Workflow. Wenn das System die Route während der Ausführung entdeckt, befinden Sie sich im Agent-Bereich und sollten sofort zusätzliche Kontrollschichten einplanen.
Behandeln Sie Evaluations wie Unit Tests für Verhalten.
Die Qualität eines Agenten driftet, wenn man keine Regression Suite pflegt, keine Transcripts liest und wichtige Szenarien nicht kontinuierlich testet. Das merkt man besonders dann, wenn sich Modelle, Prompts oder Tools ändern. [8]
Fazit
Im Inneren eines KI-Agenten steckt keine Magie. Es ist ein Zyklus, umhüllt von Zustand, Regeln, Tools und einer Control Plane. Probleme beginnen dort, wo Teams nur die Schleife shippen und alles drum herum vergessen.
Auf Mindestniveau oft ja. In der Engineering-Praxis beschreibt das aber nur die Untergrenze. Ein ernsthafter Agent braucht in der Regel zusätzlich State-Policy, Tracing, Freigaben, Recovery-Pfade und Evaluation Logic.
Sie konzentrieren sich meist auf das Modell und die Tools, übersehen aber die Runtime darum herum. Speicherpolitik, Checkpoints, Observability und Approvals sind oft wichtiger als noch ein weiterer Prompt-Trick.
Ein Workflow ist die bessere Wahl, wenn die Route bereits bekannt ist und explizit im Code bleiben soll. Ein Agent ist sinnvoll, wenn der Weg selbst erst während der Ausführung entdeckt werden muss und die zusätzliche Control-Plane-Komplexität gerechtfertigt ist.
Weil Agenten über viele Schritte, Tools und Zwischenzustände handeln. Ohne Evals merken Teams Regressionen oft erst dann, wenn sie Nutzer oder teure Production-Umgebungen bereits getroffen haben.
Primäre Quellen für diesen Artikel. Geprüft am 20. März 2026.
Verwandte Artikel
AI Assistant Entwicklung Kosten 2026: RAG, Knowledge Base, Integrationen und Support
Praktischer Leitfaden zu Kosten fuer AI Assistants: RAG, Knowledge Base, Channels, Tool Use, Guardrails, Evaluations, Monitoring und Support.
AI-assisted Attacks und Prompt Injection 2026: neue Angriffsfläche für AI-Produkte
AI-assisted Attacks und Prompt Injection 2026: neue Angriffsfläche für AI-Produkte. Ein praktischer PAS7-Studio-Sicherheitsleitfaden mit Threat Model, Kontrollen, Rollout-Checklist, Fehlern und Quellen.
KI fur Landingpage-Entwicklung: wo sie Launches beschleunigt und wo sie Conversion schadet
Eine praxisnahe Analyse zur Nutzung von KI fur Landingpages: v0, Webflow AI, Builder.io, Framer-ahnliche Builder, UX-Generierung, Copy, SEO, Personalisierung, A/B-Tests, Template-Risiken, Accessibility, Security und technischer Schuldenaufbau.
AI SEO / GEO im Jahr 2026: Ihre nächsten Kunden sind nicht Menschen — sondern Agents
Suche verschiebt sich von Klicks zu Antworten. Bots und AI-Agents crawlen, zitieren, empfehlen — und kaufen zunehmend. Erfahren Sie, was AI SEO / GEO bedeutet, warum klassisches SEO nicht mehr reicht und wie PAS7 Studio Marken im agentischen Web sichtbar macht.
Professionelle Entwicklung für Ihr Geschäft
Wir erstellen moderne Web-Lösungen und Bots für Unternehmen. Erfahren Sie, wie wir Ihnen helfen können, Ihre Ziele zu erreichen.