Розбираємося чому Timber так сильно пришвидшує ML-моделі
Практичний розбір компілятора Timber. На основі самого репозиторію пояснюємо, чому Timber може зводити inference classical ML майже до мікросекунд і звідки реально береться цей приріст.
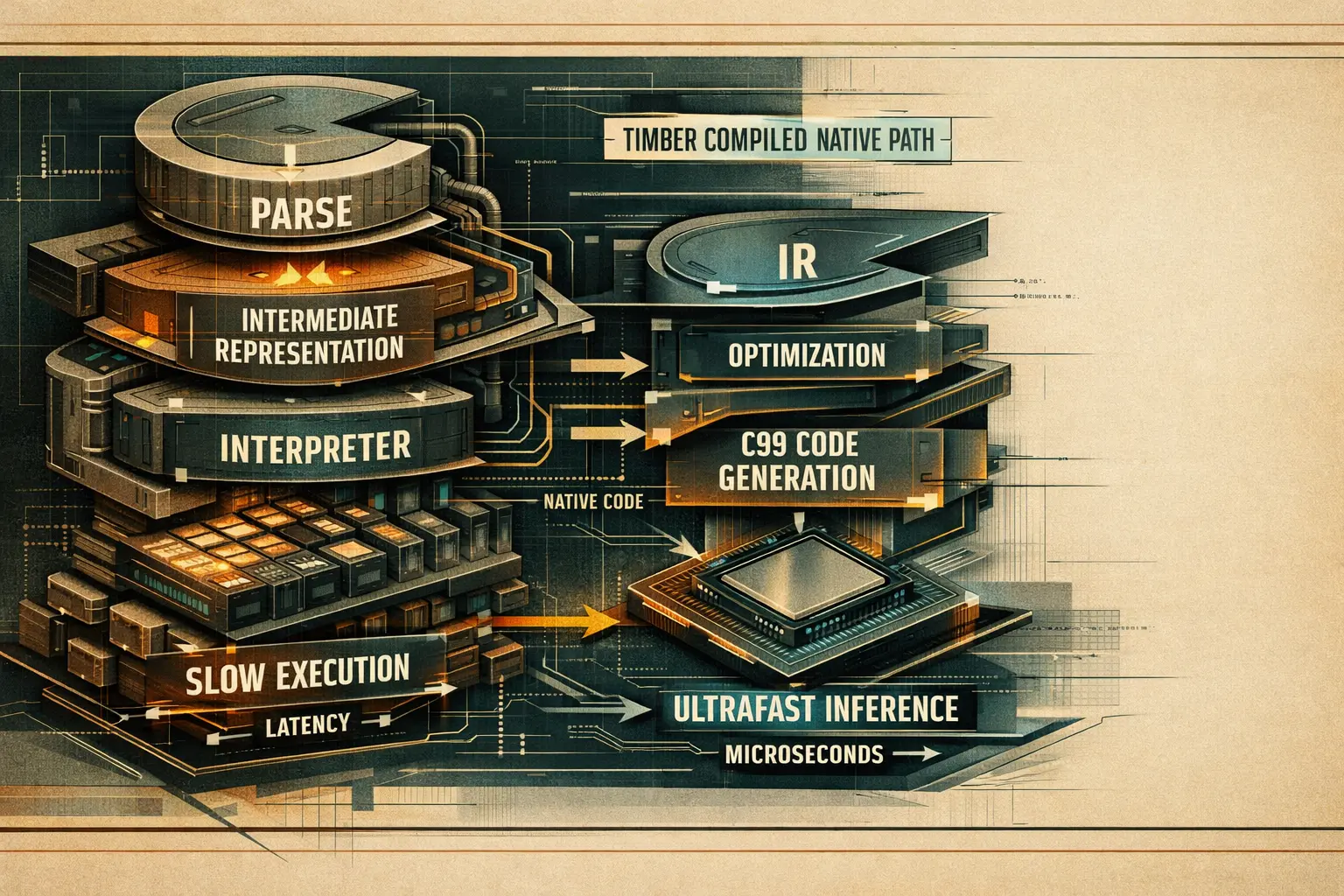
Ось що варто зрозуміти одразу.
• Timber це не прискорювач для LLM. Це компілятор для classical ML inference. [4][5]
• Приріст швидкості базується на простій ідеї, яку добре довели до кінця: один раз розпарсити натреновану модель, один раз оптимізувати граф, один раз згенерувати native C, а далі назавжди прибрати Python-heavy hot path. [4][5][6][7]
• Їхній власний benchmark headline сильний: ~2 мікросекунди на single-sample inference, ~336x швидше за Python XGBoost і ~48 KB для скомпільованого артефакту в референсному сетапі. [4]
• Причини на рівні репозиторію дуже конкретні: dead leaf elimination, threshold quantization, branch sorting, pipeline fusion, плоске array-представлення дерев, відсутність heap allocation, відсутність recursion, contiguous float32 inputs і прямі
ctypesвиклики в compiled code. [5][6][7]• Важливий нюанс такий: benchmark міряє in-process single-sample latency, а не повний end-to-end network serving. Для цього сетапу цифри реальні, але це не універсальна production-обіцянка. [8][9]
Перша важлива корекція тут концептуальна. Timber це не просто ще один Python package, який обгортає XGBoost і якось змушує його працювати швидше. Репозиторій прямо подає його як multi-stage compiler для classical ML моделей. Серед підтримуваних входів є XGBoost, LightGBM, scikit-learn, CatBoost і ONNX для trees, linear models та SVMs. На виході отримуємо self-contained C99 inference artifact без runtime dependencies. [4][5]
Ця архітектура важлива, бо вона змінює саме місце, де сидить вартість виконання. Велика частина latency у звичних Python model-serving стеках це не сама математика моделі. Це комбінація Python runtime overhead, framework abstractions, object dispatch, незручного memory layout і загальних serving-шарів навколо моделі. Timber атакує весь цей стек одразу, компілюючи модель у простіший шлях виконання. [4][5][7]
Власний high-level flow у репозиторії сформульований прямо: frontend parser -> Timber IR -> optimizer passes -> backend emitter -> native compile -> thin serve path. Це значно агресивніший підхід, ніж просто експорт у ще один runtime. [5]
Архітектура Timber спеціально побудована як компілятор. Саме через це latency-профіль так сильно змінюється. [5]
Скріншот секції what-timber-isТут немає одного магічного трюку. Результат з'являється через кілька рішень, які послідовно прибирають runtime-роботу шар за шаром.
1. Timber видаляє зайві гілки ще до першого predict
Optimizer pipeline запускає passes на кшталт dead leaf elimination і constant feature detection. Якщо обидві гілки node у підсумку дають однаковий результат, node перетворюється на leaf. Якщо calibration data показує, що feature фактично стала константою, Timber може одразу піти в deterministic child. Менше branching означає менше роботи на inference. [6]
2. Timber вбудовує preprocessing прямо в модель
Один із найважливіших passes це pipeline fusion. Якщо scaler stage стоїть прямо перед tree ensemble, Timber переписує thresholds і повністю прибирає scaler computation із runtime. Це дуже сильна оптимізація, бо стирає цілий preprocessing stage, а не лише кілька інструкцій. [5][6]
3. Timber підлаштовує форму branch-ів під CPU
Коли доступні calibration data, Timber може перевпорядкувати left і right children так, щоб частіший шлях став природним напрямком branch. На папері це виглядає як дрібниця, але саме в hot inference loops такі виграші на branch prediction добре накопичуються. [5][6]
4. Timber звужує дані там, де це безпечно
Threshold quantization намагається downcast-ити float64 thresholds до float32, але лише тоді, коли calibration data показує, що це не змінює split decision. Це зменшує розмір моделі й може покращити cache behavior без тихого спотворення predictions. [5][6]
Більше роботи наперед
Timber витрачає ресурси один раз на parse та optimization, щоб під час inference виконувати менше дій. [5][6]
Плоскі статичні масиви
Nodes зберігаються як array data, а не як pointer-heavy heap structures, що покращує locality і прибирає allocation overhead. [5]
Без recursion
Згенерований traversal ітеративний і bounded, а значить дешевший і безпечніший для tight loops та embedded targets. [5]
Тонкий ctypes міст
Numpy arrays переводяться в contiguous float32 і передаються як raw pointers прямо в compiled code. [7]
Цей репозиторій справді варто читати, бо performance-story тут не лише маркетингова. Оркестрація optimizer у timber/optimizer/pipeline.py чітко показує порядок: dead_leaf_elimination, constant_feature_detection, threshold_quantization, опціональний frequency_branch_sort, pipeline_fusion, а потім vectorization_analysis. Порядок логічний. Спочатку спрощуємо структуру дерева, потім стискаємо представлення, далі покращуємо branch direction і лише після цього ф'юзимо stages. [6]
Runtime path у timber/runtime/predictor.py не менш показовий. Inputs переводяться в contiguous float32 numpy arrays. Outputs виділяються наперед. Predictor отримує raw pointers через .ctypes.data_as(...) і викликає timber_infer або timber_infer_single напряму. У hot path майже немає Python object choreography, окрім одноразового marshaling масивів. [7]
Короткий уривок із цього потоку виглядає так:
X = np.ascontiguousarray(X, dtype=np.float32)
outputs = np.zeros((n_samples, self.n_outputs), dtype=np.float32)
inputs_ptr = X.ctypes.data_as(ctypes.POINTER(ctypes.c_float))
outputs_ptr = outputs.ctypes.data_as(ctypes.POINTER(ctypes.c_float))
rc = self._lib.timber_infer(inputs_ptr, n_samples, outputs_ptr, self._ctx)Це зовсім інший шлях, ніж залишатися всередині повного Python ML framework для кожного окремого prediction. Суть тут не лише в native code. Суть у native code плюс значно тонший call chain. [7]
У documentation по architecture також прямо сказано, що згенерований C-код використовує static const arrays, не має heap allocation, не має recursion і використовує double-precision accumulation там, де це потрібно для numerical stability. Тобто Timber не міняє швидкість на очевидні компроміси в коректності. [5]
Репозиторій робить те, що багато performance-проєктів оминають. Він відкрито показує benchmark methodology у коді. Benchmark runner тренує reference XGBoost classifier на sklearn.datasets.load_breast_cancer, використовуючи 50 trees, max depth 4, 30 features, 1,000 warmup iterations і 10,000 timed single-sample predictions. Міряються mean, p50, p95, p99 і throughput у мікросекундах. [8][9]
| Runtime | Headline з Timber docs | Що це реально означає |
|---|---|---|
| Timber native C | ~2 мікросекунди | In-process, single-sample inference через compiled native code. [4][8][9] |
| Python XGBoost | ~670 мікросекунд | Python baseline у тому ж benchmark script. [4][9] |
| Treelite | ~10 до 30 мікросекунд | Опціональний compiled baseline, якщо встановлений. [4][8] |
| ONNX Runtime | ~80 до 150 мікросекунд | Опціональний baseline у benchmark docs. [4][8] |
| HTTP serving overhead | Не входить у headline | README прямо каже, що network overhead додає приблизно 50 до 200 мікросекунд залежно від stack. [4] |
Саме через останній рядок серйозний читач не має права переобіцяти. Benchmark Timber усе одно дуже корисний, бо ізолює сам inference engine. Але якщо потім поставити модель за реальним API gateway, JSON serialization, auth, чергами і cross-process hops, фінальний latency budget уже буде іншим. [4][8]
Архітектура сильна, але це не універсальна магія для будь-якого ML стеку.
Де підхід дуже влучний
Де це не прямий fit
Дисципліна benchmark-ів усе ще важлива
Ні. Репозиторій сфокусований на classical ML сімействах на кшталт tree ensembles, linear models і SVMs. Уся логіка оптимізації в цій статті прив'язана саме до них, а не до будь-яких можливих моделей. [4][5]
Ні, якщо читати цифру в її власному контексті. Репозиторій документує reference benchmark, де Timber native inference приблизно у 336 разів швидша за Python XGBoost. Важливий нюанс у тому, що це in-process single-sample latency, а не повна network request latency. [4][8][9]
Найбільша причина в тому, що Timber переносить роботу з runtime у compile time. Вона парсить модель у власний IR, проганяє optimizer passes, генерує C99, а потім віддає значно тонший native inference path. [5][6][7]
Треба benchmark-ити свій реальний request path, а не лише isolated model inference. Міряйте in-process latency, network overhead, serialization cost, batch shape і concurrency behavior на власному hardware. Сам репозиторій теж радить публікувати методологію та hardware details разом із цифрами. [8][9]
Primary sources і файли репозиторію, на яких побудована фактична частина цього матеріалу. Threads-посилання нижче залишене як контекст для подачі, а не як доказова база для технічних тверджень.
Пов'язані статті
Скільки коштує розробка AI асистента у 2026: RAG чатбот, база знань, CRM, Telegram та підтримка
Практичний гід для бізнесу: від чого залежить ціна розробки AI асистента у 2026 році, що входить у RAG чатбот, інтеграції з CRM, Telegram, guardrails, оцінювання, моніторинг і супровід.
AI-assisted attacks і prompt injection у 2026: нова поверхня атак для продуктів з AI
Практичний гайд з безпеки AI-функцій: prompt injection, tool abuse, excessive agency, RAG poisoning, data leakage, output handling, human approval gates і permissions для AI agents.
AI для розробки лендінгів: де він реально прискорює запуск, а де псує конверсію
Дослідження про використання AI у розробці лендінгів: v0, Webflow AI, Builder.io, Framer-подібні AI builders, генерація UX, copy, SEO, персоналізація, A/B тести, ризики шаблонності, безпеки, доступності та технічного боргу.
AI SEO / GEO у 2026: ваші наступні клієнти — не люди, а агенти
Пошук зміщується від кліків до відповідей. Боти та AI-агенти сканують, цитують, рекомендують і дедалі частіше купують. Дізнайтесь, що таке AI SEO / GEO, чому класичного SEO вже недостатньо, і як PAS7 Studio допомагає брендам перемагати у «агентному» вебі.
Професійна розробка для вашого бізнесу
Створюємо сучасні веб-рішення та боти для бізнесу. Дізнайтеся, як ми можемо допомогти вам досягти цілей.