Що насправді всередині AI-агента
Практичний розбір того, з чого насправді складається AI-агент у 2026 році: цикл рішень, інструменти, пам'ять, checkpoints, правила, погодження, трасування, evals і межа між workflow та повноцінним agent runtime.
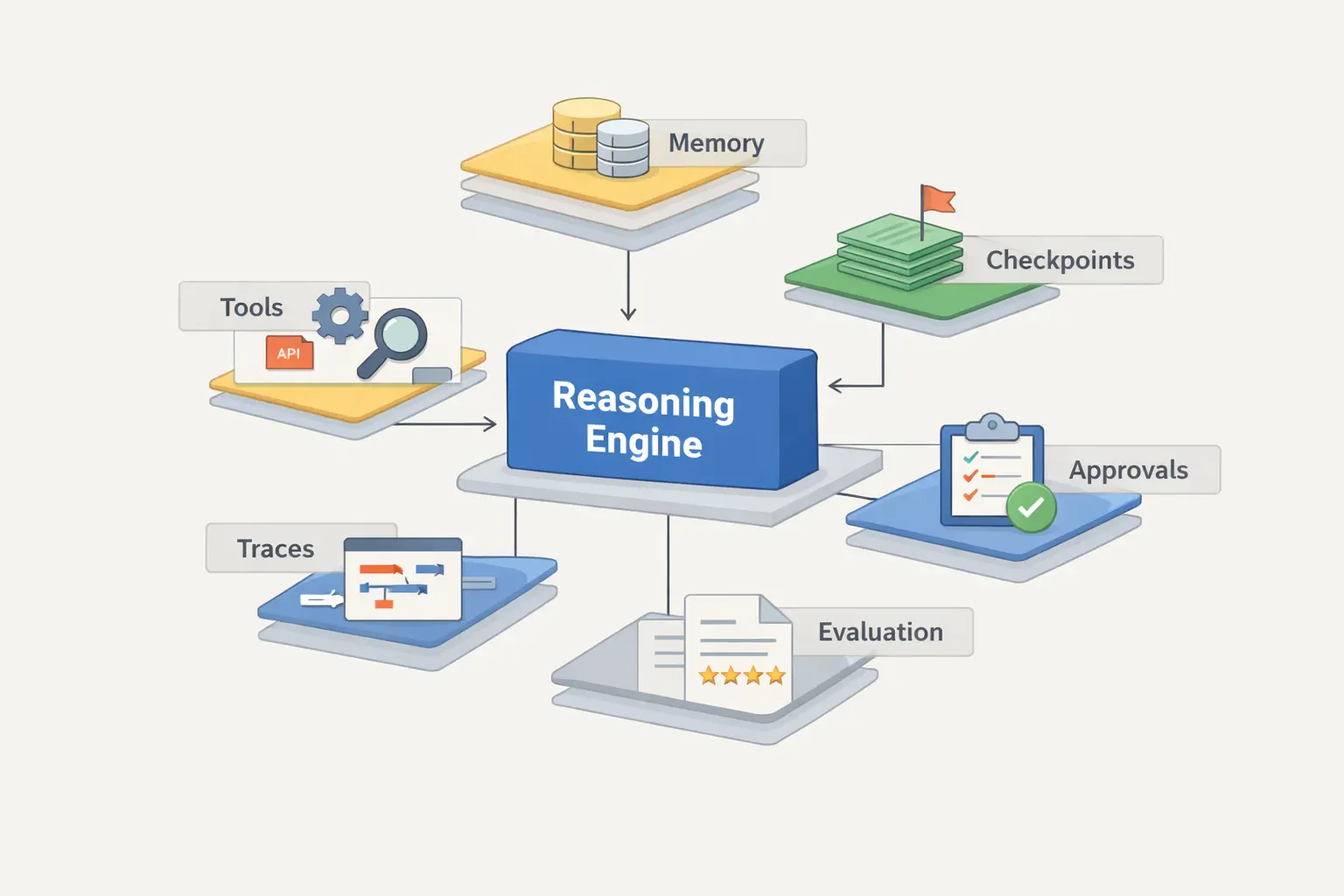
прочитайте спочатку
Найтиповіша помилка тут проста: побачити модель з tool calling і відразу назвати це агентом. Для демо цього вистачає. Для системи, яка має тримати стан, відновлюватися після невдалого кроку, просити погодження і залишати зрозумілий слід після збою, цього вже замало.
Плутанина починається з того, що різні спільноти називають словом agent різні шари системи. Для одних агентом є будь-який цикл, який уміє викликати інструменти. Для інших агентом уже вважається керований runtime з політиками, погодженнями, пам'яттю та observability. Обидва підходи описують реальну річ, але говорять про різний масштаб.
У статті на DOU грунтовно пояснений базовий цикл, а в коментарях з'являється важливе заперечення: серйозний агент це не просто 'мозок у циклі', а керована одиниця виконання з явними операційними межами. [1] Саме через це прості демо і production-системи відчуваються як різні класи продуктів.
Anthropic останнім часом тримається доволі простої нижньої межі: агент це LLM, яка автономно використовує інструменти в циклі. [2] Це корисне базове визначення. Воно добре відділяє агента від one-shot completion. Але це все ще тільки нижня межа, а не повний опис системи.
Практично це можна позначити так: агент починається з циклу, а справді корисний продукт починається з runtime навколо нього. Щойно система вміє шукати, читати, писати, виконувати код і багаторазово викликати API, основні проблеми зміщуються з якості генерації в контроль, стан і обробку збоїв.
У центрі системи є повторюваний цикл. Заходить запит або ціль. Модель дивиться на поточний контекст. Обирає наступну дію. Це може бути звичайна відповідь, структурований результат або виклик інструменту. Потім середовище повертає нове спостереження, і цикл повторюється доти, доки не спрацює умова зупинки.
Саме цей шматок люди найчастіше й бачать. Його ж найпростіше пояснити. В Anthropic-статті про Agent SDK типовий feedback loop описаний як 'зібрати контекст -> виконати дію -> перевірити результат -> повторити'. [3] Для багатьох production-агентів це дуже точна спрощена картинка, навіть якщо обв'язка навколо циклу далі стає значно складнішою.
Мінімальна реалізація справді може бути короткою. Базовий цикл із tools, станом підказки та лімітом на кількість кроків вміщується у відносно невеликий шматок коду. [1] Але короткий код не означає просту систему. Це лише означає, що складність винесли в окремі сервіси, контракти інструментів, обробку пам'яті й операційні запобіжники.
Ось максимально спрощена версія механізму. Вона коротка, щоб межі були добре видні:
messages = [system_prompt, user_request]
steps = 0
while steps < MAX_STEPS:
response = model.run(messages=messages, tools=TOOLS)
if response.final_output:
return response.final_output
if response.tool_calls:
for call in response.tool_calls:
result = run_tool(call.name, call.arguments)
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": serialize(result),
})
else:
messages.append(response.message)
steps += 1
raise RuntimeError("Agent exceeded max steps")Якщо прочитати тільки цей цикл, буде зрозуміло, з чого агент починається. Але цього ще недостатньо, щоб зрозуміти, чому один агент стабільний, інший дорогий, а третій тихо накопичує ризик і ламається під час кожного запиту.
Висновок
Цикл пояснює поведінку агента. Але сам по собі ще не пояснює його якість, вартість і безпеку.
Щойно ви виходите за межі іграшкових агентів, ключове питання вже не в тому, чи може модель викликати інструмент. Питання стає іншим: за якими правилами їй взагалі дозволено діяти, який стан вона тягне за собою, що саме зберігається, що потребує погодження і як ви розбиратимете невдалий запуск уже після збою.
Березневий реліз OpenAI про building agents тут дуже показовий. В анонсі йдеться не тільки про model calls. Окремо підсвічені built-in tools, orchestration та integrated observability для трасування виконання workflow. [4] Це важливий сигнал: навіть платформи подають побудову агентів як runtime-задачу, а не просто як вправу з промптами.
Той самий патерн видно і у framework docs. LangGraph у документації про persistence говорить про checkpoints, threads, replay, time travel і fault tolerance. [6] Microsoft Agent Framework ставить observability в центр і веде traces, logs та metrics через OpenTelemetry. [7] Це не бонусні фічі. Це те, що дозволяє команді дебажити, відновлювати, переглядати та контролювати довгі запуски.
Робоча модель тут така: зверху ціль і дозволи, нижче policy планування, потім доступ до інструментів, далі стан і пам'ять, а поверх цього всього control plane з tracing, evals, approvals і rollback. Модель дуже важлива, але вона лише один шар усередині цієї конструкції.
Висновок
Що більше свободи ви даєте агенту, то більше runtime-обв'язки має бути навколо моделі.
Це розділення справді важливе, бо команди дуже часто тягнуть agent-інфраструктуру в задачі, які насправді є просто workflow. У підсумку система стає дорожчою і складнішою для тестування, але не отримує достатньо додаткових можливостей, щоб це виправдати.
Workflow
Agent runtime
Погана середина
Система виглядає автономною, але не має чітких дозволів, правил зупинки, replayable history і нормальної поверхні для review. Саме тут команди отримують дорогі демо, яким важко довіряти і ще важче їх дебажити.
Практичне правило
Якщо шлях уже відомий, починайте з workflow. До агента варто йти тільки тоді, коли сам маршрут треба відкривати вже під час виконання системи.
| Comparison point | Що це зазвичай означає | Чому це важливо |
|---|---|---|
| Поточне context window | Активна підказка, недавні повідомлення, результати інструментів і робочий стан поточного запуску. | Саме це найшвидше ламається, коли агент занадто довго крутиться або накопичує шум із tool output. [1][5][9] |
| Checkpoints або thread state | Збережені snapshots виконання, з яких запуск можна продовжити, replay-нути або розібрати пізніше. | Саме це робить людське погодження, переривання, дебаг і відновлення після збою практичними. [6] |
| Long-term memory store | Довші факти, користувацькі вподобання або summaries, які лежать поза межами поточного context window. | Це корисно, коли агенту потрібна тяглість між сесіями, але небезпечно, якщо політика пам'яті розмита або дані застарівають. [5][6] |
Цей шар перетворює автономне демо на інженерну систему. Якщо цих частин немає в production йому буде важко.
Немає межі для погодження. Якщо агент може робити side effects без людського review там, де review потрібен, система дуже швидко стає крихкою.
Немає дисципліни evals. Anthropic прямо пише, що capability evals, regression suites, review transcript-ів і постійні перевірки перестають бути опцією, коли система вже справді важлива. [8]
Немає rollback або recovery path. Якщо крок падає посеред процесу, а система не вміє resume або replay from known state, оператор залишається майже сліпим. [6]
Висновок
Що більше автономії ви даєте, то більше control plane потрібно навколо неї. Інакше система буде agentic лише в найменш корисному сенсі: вона діє сама, але нормально керувати нею ніхто не може.
Якщо вам потрібен один пункт, який можна використати на architecture review, беріть саме цей.
Спочатку запитайте, де саме визначається шлях.
Якщо маршрут здебільшого вже зафіксований у коді, називайте це workflow. Якщо система відкриває маршрут уже під час виконання, ви зайшли на територію агентів і маєте одразу закладати бюджет на додаткові контрольні шари.
Ставтеся до evaluations як до unit tests для поведінки.
Якість агента дрейфує, якщо не тримати regression suite, не читати transcripts і не проганяти ключові сценарії постійно. Це особливо помітно, коли міняються models, prompts або tools. [8]
Суть
Всередині AI-агента немає магії. Там є цикл, обгорнутий станом, правилами, інструментами і control plane. Команди починають мати проблеми тоді, коли деплоять сам цикл і забувають про все, що має бути навколо нього.
На мінімальному рівні часто так. Але в інженерній практиці це описує лише нижню межу. Серйозний агент зазвичай ще потребує політики стану, tracing, погоджень, шляхів відновлення і evaluation logic.
Зазвичай вони дивляться на модель і інструменти, але пропускають runtime навколо них. Політика пам'яті, checkpoints, observability і approvals часто важливіші, ніж ще один трюк із промптом.
Workflow краще брати тоді, коли маршрут уже відомий і має залишатися явним у коді. Агент потрібен там, де сам маршрут треба відкривати вже під час виконання і де додаткова складність control plane справді виправдана.
Бо агенти діють через багато кроків, інструментів і проміжних станів. Без evals команди часто помічають регресії вже після того, як вони зачепили користувачів або дороге production-середовище.
Основні джерела, використані в цій статті. Перевірено 20 березня 2026 року.
Пов'язані статті
Скільки коштує розробка AI асистента у 2026: RAG чатбот, база знань, CRM, Telegram та підтримка
Практичний гід для бізнесу: від чого залежить ціна розробки AI асистента у 2026 році, що входить у RAG чатбот, інтеграції з CRM, Telegram, guardrails, оцінювання, моніторинг і супровід.
AI-assisted attacks і prompt injection у 2026: нова поверхня атак для продуктів з AI
Практичний гайд з безпеки AI-функцій: prompt injection, tool abuse, excessive agency, RAG poisoning, data leakage, output handling, human approval gates і permissions для AI agents.
AI для розробки лендінгів: де він реально прискорює запуск, а де псує конверсію
Дослідження про використання AI у розробці лендінгів: v0, Webflow AI, Builder.io, Framer-подібні AI builders, генерація UX, copy, SEO, персоналізація, A/B тести, ризики шаблонності, безпеки, доступності та технічного боргу.
AI SEO / GEO у 2026: ваші наступні клієнти — не люди, а агенти
Пошук зміщується від кліків до відповідей. Боти та AI-агенти сканують, цитують, рекомендують і дедалі частіше купують. Дізнайтесь, що таке AI SEO / GEO, чому класичного SEO вже недостатньо, і як PAS7 Studio допомагає брендам перемагати у «агентному» вебі.
Професійна розробка для вашого бізнесу
Створюємо сучасні веб-рішення та боти для бізнесу. Дізнайтеся, як ми можемо допомогти вам досягти цілей.