Сабагенти в Codex: як це працює насправді
Практичний розбір сабагентів у OpenAI Codex у 2026 році: що саме випустив OpenAI, як ними користуватися, де вони реально дають виграш, де тільки додають шум, і як це впливає на ліміти, кредити та швидкість роботи.
прочитати спочатку
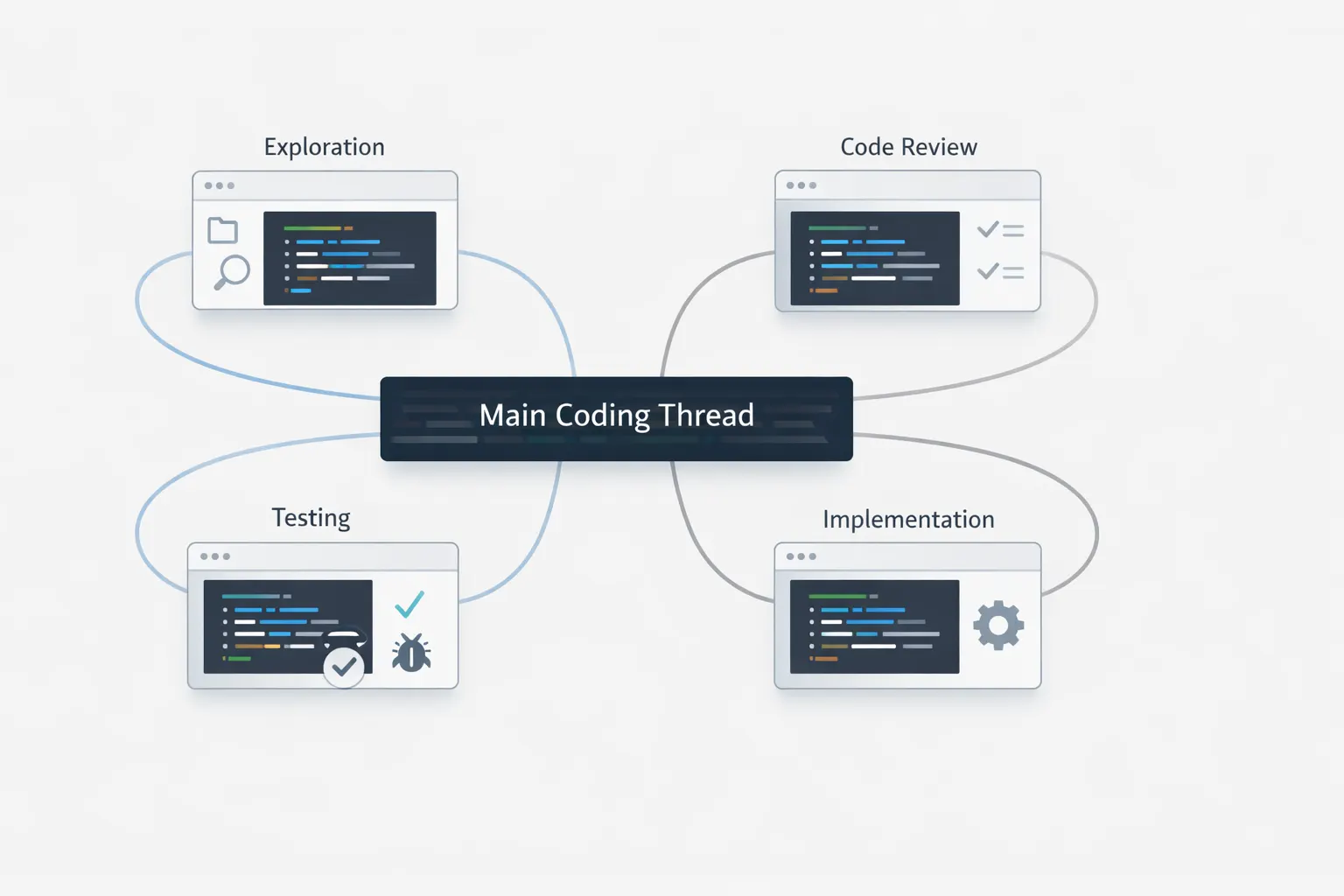
Спершу слід сказати, що суть не в тому, що Codex навчився відкривати більше потоків. Суть у тому, що OpenAI формалізував спосіб тримати головний потік чистим, поки паралельна робота відбувається окремо. Це одночасно впливає на надійність, швидкість і витрату лімітів.
У продуктовому формулюванні OpenAI все сказано прямо. В анонсі Codex app компанія пише, що застосунок створений, щоб manage multiple agents at once, run work in parallel і працювати з довгими задачами. [4] Це абсолютно новий перемикач в інтерфейсі. А також зміна того, як Codex пропонує розкладати велику інженерну роботу.
У технічній документації причина пояснена ще простіше. Навіть якщо контекстне вікно велике, основний контекст псується, коли туди постійно складати логи, трасування, чернеткові гіпотези, проміжні перевірки й тестовий шум. OpenAI називає дві конкретні проблеми: context pollution і context rot. [1]
Це добре стикується і з незалежними дослідженнями. У звіті Chroma Context Rot прямо показано, що зі зростанням обсягу вхідного контексту надійність відповіді починає просідати, особливо на складніших задачах. [8] По суті, сабагенти в Codex це продуктова відповідь OpenAI на цю інженерну реальність.
Anthropic у своєму Agent SDK описує дуже схожий підхід з іншого боку: сабагенти корисні для parallelization і для керування контекстом, бо працюють у their own isolated context windows. [11] Тобто вже не одна компанія просуває таку ідею. Це стає загальним патерном для довгих агентних workflow.
Якщо прибрати брендинг, модель досить проста: один головний потік оркеструє роботу, один або кілька дочірніх потоків роблять чітко обмежені задачі, а потім батьківський потік збирає все назад у фінальний результат.
Тримайте основний потік для вимог і фінального рішення
Головний потік має нести brief, обмеження, архітектурні рішення й фінальне зведення. Документація OpenAI прямо позиціонує сабагентів як спосіб залишити в основному потоці саме вимоги, рішення й підсумок. [1]
Давайте кожному сабагенту вузьку задачу
У документації є показовий приклад з review pull request, де Codex запускає окремого агента під security, bugs, race conditions, flaky tests і maintainability. Саме так це і має працювати: одна чітка задача на один дочірній потік. [2]
Перемикайтеся в дочірні потоки, якщо треба перевірити або скоригувати їх
У CLI команда /agent дозволяє перейти в активний агентний потік, подивитися, що він робить, і продовжити роботу вже там. Це також важливо, бо делегування не означає сліпу довіру. Критичні рішення все одно треба мати можливість перевірити. [6]
Нехай батьківський потік збере все в один підсумок
OpenAI вказує, що після завершення потрібної роботи Codex повертає вже консолідовану відповідь: паралельна робота знизу, один чистий summary зверху. [2]
Висновок
Головний потік має поводитися як lead engineer. Сабагенти мають працювати як вузько сфокусовані спеціалісти, а не як вільні копії головного агента.
Дана частина важлива, бо сабагенти вже не виглядають як прихована внутрішня магія. OpenAI задокументував і вбудовані ролі, і поверхню конфігурації навколо них.
Вбудовані ролі вже є
OpenAI описує три built-in агенти: default для загальної роботи, worker для execution-heavy задач і фіксів, та explorer для read-heavy дослідження кодової бази. [2]
Можна додавати своїх агентів
Custom agents живуть у ~/.codex/agents/ для персонального використання або в .codex/agents/ на рівні проєкту. Кожен з них описує name, description, developer_instructions, а також може перевизначати model, reasoning effort, sandbox mode, MCP servers і skills. [2]
Паралелізм теж налаштовується
OpenAI документує налаштування [agents], зокрема max_threads, max_depth і job_max_runtime_seconds. За замовчуванням max_threads дорівнює 6, а max_depth дорівнює 1, щоб не допускати глибокої рекурсії без потреби. [2]
Сабагенти наслідують safety controls
Сабагенти наслідують поточну sandbox policy. Approval prompts можуть приходити і з неактивних потоків, а глибока рекурсія окремо не рекомендується, бо швидко збільшує витрату токенів, затримки й локальне навантаження. [2]
У багатьох команд з'являються помилкові очікування. Бо на платних ChatGPT планах реальна проблема зазвичай не в абстрактній API-математиці токенів, а в тому, як швидко сабагенти спалюють включені ліміти або кредити.
| Comparison point | Що пише OpenAI | Що це означає на практиці |
|---|---|---|
| Сценарії з сабагентами | Споживають більше токенів, ніж подібний сценарій в одному потоці. [1][2] | Паралельне делегування корисне, але це не безкоштовне прискорення. Кожен дочірній потік виконує власний model і tool loop. |
| GPT-5.4-mini | Використовує близько 30% тих включених лімітів, які витрачає GPT-5.4, і може працювати приблизно в 3.3 раза довше до упору в ліміти. [3] | Хороший базовий вибір для легших сабагентів: exploration, review великих файлів, опорні документи, secondary analysis. |
| Локальна вартість GPT-5.4 | У середньому близько 7 credits за local task. [7] | Сильний вибір для головного потоку, але дорогий, якщо бездумно розкидати його на кілька дочірніх потоків одночасно. |
| Локальна вартість GPT-5.4-mini | У середньому близько 2 credits за local task. [7] | Набагато логічніший вибір, якщо сабагент робить допоміжну, а не фінальну роботу. |
| Локальна і cloud вартість GPT-5.3-Codex | У середньому близько 5 credits за local task і близько 25 за cloud task. [7] | Все ще сильний вибір для справді важких software engineering задач, особливо якщо потрібен кодинг-first профіль замість ширшого GPT-5.4 профілю. |
| Fast mode на GPT-5.4 | Дає приблизно 1.5x швидкість і 2x credit rate. [5] | Підходить для latency-sensitive роботи, але ще сильніше прискорює витрату кредитів поверх і так дорожчого subagent fan-out. |
Сабагенти це не універсальний апгрейд. Це інструмент координації.
Сильний fit
Варто тестувати
Великі фічі, де один дочірній потік може забрати UI, другий backend, а третій підготувати тести або migration notes. Це працює тільки якщо кордони справжні, а фінальний judgment лишається в батьківському потоці.
Часто overkill
Дрібні зміни, баги в одному файлі, швидкі refactor-и або будь-яка задача, де головна складність не в масштабі, а в ясності. Тут делегування часто коштує дорожче, ніж просто зробити роботу одним потоком.
Зона підвищеного ризику
Паралельна write-heavy робота в одній і тій самій поверхні коду. OpenAI прямо попереджає, що одночасні edits можуть створювати конфлікти й збільшувати координаційний overhead. [1]
Найтиповіша помилка тут проста: користувачі просять про допомогу сабагентів занадто розмито. Робочий патерн завжди однаковий: описати split, дати кожному дочірньому потоку чіткі межі й пояснити, який саме обʼєм роботи має повернутися в головний потік.
Для PR review хороший prompt може виглядати так:
Spawn three subagents.
Agent 1: review security issues and secret handling.
Agent 2: review race conditions and concurrency risks.
Agent 3: review test gaps and flaky cases.
Return one merged summary with the most important findings first.Для implementation work важливо розвести ownership:
Use two subagents.
Agent 1 owns the API handler and schema changes.
Agent 2 owns the frontend form and validation wiring.
Do not edit the same files. Summarize conflicts before making final edits.Для research-heavy задач логічно одразу просити дешевший дочірній runtime:
Spawn one explorer subagent per document.
Extract only the constraints, breaking changes, and migration risks.
Use `gpt-5.4-mini` for all child threads, then summarize in the main thread.Нижче розписані рекомендації щодо використання сабагентів в Codex. Алгоритм тут досить простий.
Явно просіть про сабагентів і називайте split
Не пишіть просто investigate this. Пишіть щось на кшталт spawn one agent for security, one for race conditions, one for test flakiness, then summarize. Саме таку структуру запиту показує і документація Codex. [2]
Тримайте головний потік коротким і чистим
Нехай батьківський потік тримає scope, обмеження, acceptance criteria і фінальні рішення. Шумне дослідження краще виносити в дочірні потоки. [1]
Перевіряйте дочірні потоки, а не просто довіряйте summary
Використовуйте /agent у CLI, якщо щось виглядає підозріло або якщо в результаті дочірнього потоку є критичне рішення, яке не варто приймати навмання. [6]
Не розкручуйте рекурсію глибоко
OpenAI поставив max_depth у 1 за замовчуванням не випадково. Глибокий recursive fan-out дуже швидко збільшує витрату токенів, затримки й навантаження на локальні ресурси. [2]
Розділяйте read-heavy і write-heavy делегування
Найкраще спочатку паралелити саме analysis. До parallel edits варто переходити лише тоді, коли ownership між потоками достатньо чіткий і конфлікти малоймовірні. [1]
Початкові помилки можуть бути досить передбачувані. Майже всі вони виникають тоді, коли сабагенти сприймаються як безкоштовна додаткова робоча сила, а не як інструмент оркестрації.
Запускати сабагентів на розмиту задачу. Якщо завдання не має чітких меж, ви просто множите плутанину.
Паралелити edits у тих самих файлах. Документація прямо попереджає про конфлікти й координаційний overhead у write-heavy сценаріях. [1]
Ігнорувати approval і sandbox inheritance. Дочірні потоки наслідують поточну sandbox policy, а approval prompts можуть приходити з неактивних потоків. [2]
Висновок
Сабагенти працюють найкраще тоді, коли прибирають шум, а не коли просто множать активність заради активності.
Ні. У документації OpenAI прямо сказано, що Codex запускає сабагентів лише тоді, коли ви явно просите про subagents або parallel agent work. [1][2]
OpenAI зараз документує три вбудовані агенти: `default`, `worker` і `explorer`. `worker` заточений під execution-heavy роботу, а `explorer` під read-heavy дослідження кодової бази. [2]
Зазвичай так. OpenAI пише, що workflow із сабагентами споживають більше токенів, ніж схожі сценарії в одному потоці, бо кожен дочірній потік виконує власний model і tool loop. На ChatGPT планах це зазвичай відчувається як швидше споживання included limits або credits. [1][2][7]
Поточна логіка OpenAI така: починати з `gpt-5.4` для головної задачі й брати `gpt-5.4-mini` для легших coding tasks або сабагентів. `gpt-5.3-codex` при цьому лишається сильним варіантом для складних software engineering задач. [3][5]
Найкраще вони працюють на parallelizable, read-heavy роботі: exploration, tests, triage, summarization і review. OpenAI прямо радить починати саме звідси й набагато обережніше ставитися до паралельної write-heavy роботи. [1]
Не зовсім. У практичному сенсі витрата росте майже завжди, але OpenAI не публікує якийсь один фіксований множник для всіх планів і всіх сценаріїв. Реальний ефект залежить від моделі, розміру задачі, обсягу контексту, local чи cloud execution і того, скільки дочірніх потоків ви запускаєте. [1][2][7]
Цей блог побудований на поточній документації й продуктових сторінках OpenAI про Codex, pricing, changelog і speed, а також на зовнішніх дослідженнях про деградацію контексту та на матеріалах Anthropic про agent SDK.
Пов'язані статті
Скільки коштує розробка AI асистента у 2026: RAG чатбот, база знань, CRM, Telegram та підтримка
Практичний гід для бізнесу: від чого залежить ціна розробки AI асистента у 2026 році, що входить у RAG чатбот, інтеграції з CRM, Telegram, guardrails, оцінювання, моніторинг і супровід.
AI-assisted attacks і prompt injection у 2026: нова поверхня атак для продуктів з AI
Практичний гайд з безпеки AI-функцій: prompt injection, tool abuse, excessive agency, RAG poisoning, data leakage, output handling, human approval gates і permissions для AI agents.
AI для розробки лендінгів: де він реально прискорює запуск, а де псує конверсію
Дослідження про використання AI у розробці лендінгів: v0, Webflow AI, Builder.io, Framer-подібні AI builders, генерація UX, copy, SEO, персоналізація, A/B тести, ризики шаблонності, безпеки, доступності та технічного боргу.
AI SEO / GEO у 2026: ваші наступні клієнти — не люди, а агенти
Пошук зміщується від кліків до відповідей. Боти та AI-агенти сканують, цитують, рекомендують і дедалі частіше купують. Дізнайтесь, що таке AI SEO / GEO, чому класичного SEO вже недостатньо, і як PAS7 Studio допомагає брендам перемагати у «агентному» вебі.
Професійна розробка для вашого бізнесу
Створюємо сучасні веб-рішення та боти для бізнесу. Дізнайтеся, як ми можемо допомогти вам досягти цілей.