Warum Timber ML-Modelle so stark beschleunigt: eine praktische Analyse
Eine praktische Analyse des Timber-Compilers. Auf Basis des Repositories selbst erklären wir, warum Timber classical ML inference fast bis in den Mikrosekundenbereich drücken kann und woher dieser Geschwindigkeitsgewinn wirklich kommt.
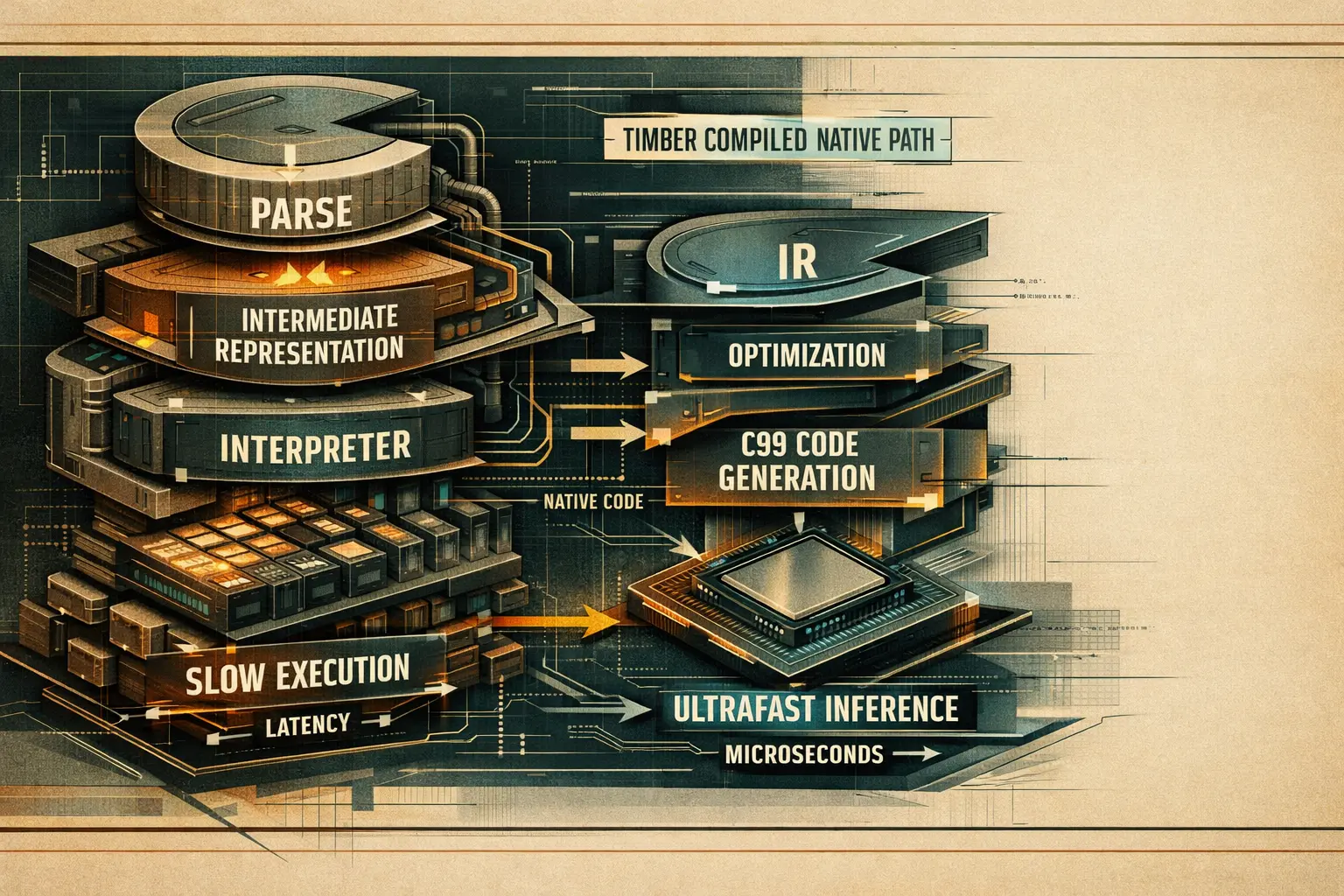
Das sollte man direkt verstehen.
• Timber ist kein Beschleuniger für LLMs. Es ist ein Compiler für classical ML inference. [4][5]
• Der Geschwindigkeitsgewinn basiert auf einer einfachen Idee, die sauber umgesetzt wurde: einmal das trainierte Modell parsen, einmal den Graph optimieren, einmal nativen C-Code erzeugen und danach den Python-heavy hot path dauerhaft entfernen. [4][5][6][7]
• Die eigene Benchmark-Zeile ist stark: ~2 Mikrosekunden single-sample inference, ~336x schneller als Python XGBoost und ein ~48 KB großes kompiliertes Artefakt im Referenz-Setup. [4]
• Die Gründe auf Repository-Ebene sind konkret: dead leaf elimination, threshold quantization, branch sorting, pipeline fusion, flache Array-Darstellung der Bäume, keine heap allocation, keine recursion, contiguous float32 inputs und direkte
ctypes-Aufrufe in compiled code. [5][6][7]• Die wichtige Einschränkung ist: Der Benchmark misst in-process single-sample latency, nicht komplettes end-to-end network serving. Für dieses Setup sind die Zahlen real, aber sie sind kein universelles Production-Versprechen. [8][9]
Die erste wichtige Korrektur ist konzeptionell. Timber ist nicht einfach noch ein Python-Paket, das XGBoost umhüllt und irgendwie schneller macht. Das Repository beschreibt es direkt als multi-stage compiler für classical ML Modelle. Unterstützt werden XGBoost, LightGBM, scikit-learn, CatBoost und ONNX für trees, linear models und SVMs. Das Ergebnis ist ein self-contained C99 inference artifact ohne runtime dependencies. [4][5]
Diese Architektur ist wichtig, weil sie verschiebt, wo die Kosten entstehen. Viel Latenz in typischen Python-Model-Serving-Stacks entsteht nicht in der Mathematik des Modells selbst. Sie entsteht aus Python runtime overhead, Framework-Abstraktionen, object dispatch, ungünstigem memory layout und allgemeinen Serving-Schichten um das Modell herum. Timber greift diesen ganzen Stack an, indem es das Modell in einen einfacheren Ausführungspfad kompiliert. [4][5][7]
Der eigene high-level flow im Repository ist eindeutig: frontend parser -> Timber IR -> optimizer passes -> backend emitter -> native compile -> thin serve path. Das ist deutlich aggressiver als ein bloßer Export in einen weiteren Runtime. [5]
Timbers Architektur ist absichtlich wie ein Compiler aufgebaut. Genau deshalb verschiebt sich das Latenzprofil so deutlich. [5]
Screenshot des Abschnitts what-timber-isEs gibt hier keinen einzelnen Zaubertrick. Das Ergebnis entsteht durch mehrere Entscheidungen, die Runtime-Arbeit Schicht für Schicht entfernen.
1. Timber entfernt unnötige Verzweigungen schon vor dem ersten Predict
Die Optimizer-Pipeline führt Passes wie dead leaf elimination und constant feature detection aus. Wenn beide Zweige eines Nodes am Ende zum selben Ergebnis führen, wird der Node zu einem Leaf. Wenn calibration data zeigt, dass ein Feature faktisch konstant ist, kann Timber direkt zum deterministic child springen. Weniger branching bedeutet weniger Arbeit zur Inference-Zeit. [6]
2. Timber faltet Preprocessing direkt in das Modell ein
Einer der wichtigsten Passes ist pipeline fusion. Wenn ein scaler stage direkt vor einem tree ensemble steht, schreibt Timber die thresholds um und entfernt scaler computation vollständig aus der runtime. Das ist eine ungewöhnlich starke Optimierung, weil ein ganzer preprocessing stage verschwindet und nicht nur ein paar Instruktionen. [5][6]
3. Timber passt die Form der Branches an die CPU an
Wenn calibration data verfügbar sind, kann Timber left und right children so umordnen, dass der häufigere Pfad zur natürlichen branch-Richtung wird. Auf dem Papier wirkt das klein, aber genau in hot inference loops summieren sich solche branch-prediction-Gewinne. [5][6]
4. Timber verkleinert Daten dort, wo es sicher ist
Threshold quantization versucht, float64 thresholds nach float32 downzucasten, aber nur dann, wenn calibration data zeigen, dass sich dadurch keine split decision ändert. Das verkleinert das Modell und kann cache behavior verbessern, ohne predictions still zu verfälschen. [5][6]
Mehr Arbeit vorab
Timber investiert einmalig Aufwand in Parse und Optimization, damit inference später weniger Arbeit leisten muss. [5][6]
Flache statische Arrays
Nodes werden als Array-Daten gespeichert statt als pointer-heavy heap structures. Das verbessert locality und entfernt allocation overhead. [5]
Ohne recursion
Der generierte traversal ist iterativ und bounded. Das ist günstiger und sicherer für tight loops und embedded targets. [5]
Dünne ctypes Brücke
Numpy-Arrays werden in contiguous float32 umgewandelt und als raw pointers direkt in compiled code übergeben. [7]
Dieses Repository lohnt sich zu lesen, weil die Performance-Story hier nicht nur aus Marketing besteht. Die Orchestrierung des Optimizers in timber/optimizer/pipeline.py zeigt die Reihenfolge klar: dead_leaf_elimination, constant_feature_detection, threshold_quantization, optional frequency_branch_sort, pipeline_fusion und danach vectorization_analysis. Die Reihenfolge ist logisch. Erst wird die Baumstruktur vereinfacht, dann die Repräsentation verdichtet, danach die branch direction verbessert und erst dann werden stages gefused. [6]
Der Runtime-Pfad in timber/runtime/predictor.py ist genauso aufschlussreich. Inputs werden in contiguous float32 numpy arrays umgewandelt. Outputs werden vorab allokiert. Der Predictor holt sich raw pointers über .ctypes.data_as(...) und ruft timber_infer oder timber_infer_single direkt auf. Im hot path gibt es fast keine Python object choreography außer dem einmaligen Marshaling der Arrays. [7]
Ein kurzer Ausschnitt aus diesem Pfad sieht so aus:
X = np.ascontiguousarray(X, dtype=np.float32)
outputs = np.zeros((n_samples, self.n_outputs), dtype=np.float32)
inputs_ptr = X.ctypes.data_as(ctypes.POINTER(ctypes.c_float))
outputs_ptr = outputs.ctypes.data_as(ctypes.POINTER(ctypes.c_float))
rc = self._lib.timber_infer(inputs_ptr, n_samples, outputs_ptr, self._ctx)Das ist ein ganz anderer Pfad, als für jede einzelne Prediction innerhalb eines vollständigen Python ML Frameworks zu bleiben. Der Punkt ist nicht nur native code. Der Punkt ist native code plus ein drastisch dünnerer call chain. [7]
In der Architecture-Dokumentation steht außerdem ausdrücklich, dass der generierte C-Code static const arrays nutzt, keine heap allocation hat, keine recursion verwendet und double-precision accumulation dort nutzt, wo es für numerical stability nötig ist. Timber tauscht Geschwindigkeit also nicht gegen offensichtliche Korrektheitsabstriche. [5]
Das Repository macht etwas, das viele Performance-Projekte auslassen. Es legt die Benchmark-Methodik direkt im Code offen. Der benchmark runner trainiert einen reference XGBoost classifier auf sklearn.datasets.load_breast_cancer mit 50 trees, max depth 4, 30 features, 1.000 warmup iterations und 10.000 timed single-sample predictions. Gemessen werden mean, p50, p95, p99 und throughput in Mikrosekunden. [8][9]
| Runtime | Headline aus den Timber docs | Was es real bedeutet |
|---|---|---|
| Timber native C | ~2 Mikrosekunden | In-process, single-sample inference durch compiled native code. [4][8][9] |
| Python XGBoost | ~670 Mikrosekunden | Python baseline im gleichen benchmark script. [4][9] |
| Treelite | ~10 bis 30 Mikrosekunden | Optionaler compiled baseline, wenn installiert. [4][8] |
| ONNX Runtime | ~80 bis 150 Mikrosekunden | Optionaler baseline in den benchmark docs. [4][8] |
| HTTP serving overhead | Nicht in der Headline enthalten | Das README sagt ausdrücklich, dass network overhead je nach stack ungefähr 50 bis 200 Mikrosekunden hinzufügt. [4] |
Gerade wegen der letzten Zeile darf man hier nicht übertreiben. Der Timber-Benchmark ist trotzdem sehr nützlich, weil er den inference engine selbst isoliert. Wenn das Modell später aber hinter einem echten API gateway, JSON serialization, auth, queues und cross-process hops läuft, sieht das finale latency budget anders aus. [4][8]
Die ehrliche Lesart lautet daher: Timber hat sehr starke Belege dafür, dass es den core inference Teil des Pfads drastisch verkleinern kann. Ob daraus in Production am Ende 5x, 20x oder 100x werden, hängt davon ab, wie viel nicht-modellbezogener Overhead in eurem Stack danach noch übrig bleibt. [4][8][9]
Die Architektur ist stark, aber sie ist keine universelle Magie für jeden ML-Stack.
Wo der Ansatz sehr gut passt
Wo es kein direkter Fit ist
Benchmark-Disziplin bleibt wichtig
Wenn man Timber gegen einen aufgeblähten Python serving path benchmarkt, wirkt der Abstand riesig. Wenn man gegen einen gut optimierten native baseline auf derselben Hardware und derselben Request-Form benchmarkt, wird der Abstand kleiner. Das entwertet Timber nicht. Es bedeutet nur, dass die Bewertung ehrlich sein muss. [8][9]
Nein. Das Repository konzentriert sich auf classical ML Familien wie tree ensembles, linear models und SVMs. Die gesamte Optimierungslogik in diesem Artikel bezieht sich genau darauf und nicht auf beliebige Modelle. [4][5]
Nein, wenn man die Zahl in ihrem eigenen Kontext liest. Das Repository dokumentiert einen reference benchmark, in dem Timber native inference ungefähr 336-mal schneller ist als Python XGBoost. Der wichtige Punkt ist, dass hier in-process single-sample latency und nicht vollständige network request latency gemessen wird. [4][8][9]
Der wichtigste Grund ist, dass Timber Arbeit von runtime in compile time verschiebt. Es parst das Modell in ein eigenes IR, führt optimizer passes aus, erzeugt C99 und liefert danach einen deutlich dünneren native inference path aus. [5][6][7]
Benchmarkt euren realen request path und nicht nur isolated model inference. Messt in-process latency, network overhead, serialization cost, batch shape und concurrency behavior auf eurer eigenen Hardware. Das Repository selbst empfiehlt ebenfalls, Methodik und Hardware-Details zusammen mit den Zahlen zu veröffentlichen. [8][9]
Primary sources und Repository-Dateien, auf denen der faktenbasierte Teil dieses Artikels aufbaut. Der Threads-Link unten bleibt als Kontext für die Aufmachung, nicht als Belegbasis für technische Aussagen.
Verwandte Artikel
AI Assistant Entwicklung Kosten 2026: RAG, Knowledge Base, Integrationen und Support
Praktischer Leitfaden zu Kosten fuer AI Assistants: RAG, Knowledge Base, Channels, Tool Use, Guardrails, Evaluations, Monitoring und Support.
AI-assisted Attacks und Prompt Injection 2026: neue Angriffsfläche für AI-Produkte
AI-assisted Attacks und Prompt Injection 2026: neue Angriffsfläche für AI-Produkte. Ein praktischer PAS7-Studio-Sicherheitsleitfaden mit Threat Model, Kontrollen, Rollout-Checklist, Fehlern und Quellen.
KI fur Landingpage-Entwicklung: wo sie Launches beschleunigt und wo sie Conversion schadet
Eine praxisnahe Analyse zur Nutzung von KI fur Landingpages: v0, Webflow AI, Builder.io, Framer-ahnliche Builder, UX-Generierung, Copy, SEO, Personalisierung, A/B-Tests, Template-Risiken, Accessibility, Security und technischer Schuldenaufbau.
AI SEO / GEO im Jahr 2026: Ihre nächsten Kunden sind nicht Menschen — sondern Agents
Suche verschiebt sich von Klicks zu Antworten. Bots und AI-Agents crawlen, zitieren, empfehlen — und kaufen zunehmend. Erfahren Sie, was AI SEO / GEO bedeutet, warum klassisches SEO nicht mehr reicht und wie PAS7 Studio Marken im agentischen Web sichtbar macht.
Professionelle Entwicklung für Ihr Geschäft
Wir erstellen moderne Web-Lösungen und Bots für Unternehmen. Erfahren Sie, wie wir Ihnen helfen können, Ihre Ziele zu erreichen.